Explicamos en este tutorial cómo extraer el texto y los metedatos de múltiples ficheros PDF. Mostramos cómo desarrollar una aplicación de indexación del texto y metadatos de ficheros PDF de forma nativa (sin necesidad de tener instalado software de terceros). Explicamos paso a paso cómo obtener el texto de un fichero PDF y sus metadatos (asunto, palabras clave, etc.) usando la DLL gratuita iTextSharp y el lenguaje de programación Microsoft Visual C# .Net 2010. Publicamos una aplicación completa de ejemplo con el código fuente en VB.Net: AjpdSoft Indexar Texto PDF C# iTextSharp.
Videotutorial AjpdSoft Indexar Texto PDF en funcionamiento
AjpdSoft Indexar Texto PDF C# iTextSharp permite obtener el texto de los ficheros PDF seleccionados, admite selección de múltiples ficheros. Permite obtener el texto en pantalla y guardarlo en fichero de texto o bien indexar el texto de los ficheros PDF y guardarlo en una base de datos ODBC. Admite cualquier motor de base de datos con soporte para ODBC: PostgreSQL, MySQL, Firebird, SQL Server, Access, SQLite, etc. A continuación mostramos un videotutorial con el funcionamiento de la aplicación:
Descarga del componente gratuito iTextSharp
Para desarrollar una aplicación de indexación del texto y metadatos de ficheros PDF (portable document format ó formato de documento portátil) usaremos la librería gratuita iTextSharp, por lo tanto necesitaremos descargar el fichero de esta librería dll. Accederemos a la URL:
http://sourceforge.net/projects/itextsharp
Descargaremos la versión más reciente de iTextSharp (iText#), en nuestro caso: iTextSharp 5.2.1. Se descargará el fichero itextsharp-all-5.2.1.zip, lo descomprimiremos. Este fichero contiene, a su vez, los siguientes ficheros comprimidos:
- itextsharp-dll-cores-5.2.1.zip
- itextsharp-dll-xtra-5.2.1.zip
- itextsharp-src-core-5.2.1.zip
- itextsharp-src-xtra-5.2.1.zip
iTextSharp está desarrollado en Microsoft Visual C# y, además, la descarga anterior incluye el código fuente completo (itextsharp-src-core-5.2.1.zip). En nuestro caso usaremos la DLL ya compilada de iTextSharp por lo que descomprimiremos el fichero "itextsharp-dll-cores-5.2.1.zip" que contiene el fichero itextsharp.dll, este será el fichero necesario para trabajar con ficheros PDF usando Microsoft Visual C#. Copiaremos este fichero a la carpeta que queramos (por ejemplo la raíz de nuestros proyectos). Más adelante deberemos seleccionarlo desde nuestro proyecto Visual C#:

Instalación de Microsoft Visual Studio .Net
Para desarrollar la aplicación que nos permita trabajar con ficheros PDF usaremos el lenguaje de programación Microsoft Visual C#. En este tutorial obtendremos el texto de los ficheros PDF seleccionados y lo guardaremos en una base de datos para su posterior consulta.
Usaremos la suite de desarrollo Microsoft Visual Studio .Net. En el siguiente tutorial explicamos cómo instalar esta suite de desarrollo:
Indexar texto fichero PDF con C# C Sharp y iTextSharp
A continuación explicaremos cómo crear un proyecto o solución en Microsoft Visual C# .Net para extraer el texto de los ficheros PDF seleccionados y mostrarlo en pantalla o guardarlo en una tabla de una base de datos para su posterior consulta y tratamiento. Para ello abriremos Visual Studio .Net, pulsaremos en el menú "Archivo" - "Nuevo proyecto":

Seleccionaremos en la parte izquierda "Otros lenguajes" - "Visual C# ", en la parte derecha seleccionaremos "Aplicación de Windows Forms" e introduciremos el nombre del proyecto, por ejemplo "AjpdSoftIndexarTextoFicherosPDF":
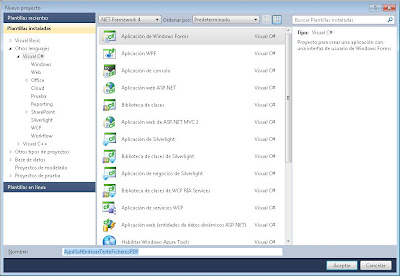
Agregaremos la referencia a iTextSharp, para ello pulsaremos en el menú "Proyecto" - "Agregar referencia":
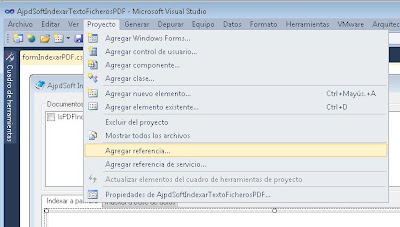
Pulsaremos en la pestaña "Examinar" y seleccionaremos el fichero "iTextSharp.dll" descargado anteriormente:
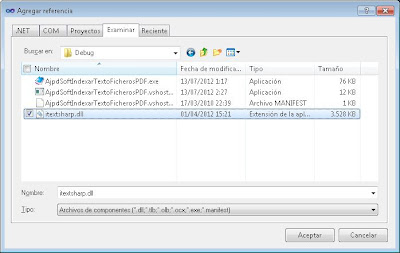
Añadiremos los "using" al proyecto, para ello pulsaremos en el menú "Ver" - "Código" y agregaremos las referencias necesarias :

Al principio agregaremos el siguiente código:
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.IO;
using System.Collections;
using System.Data.Odbc;
Añadiremos los siguientes componentes al formulario principal de nuestra aplicación para extraer el texto y metadatos de ficheros PDF: ChekedListBox, Button, GroupBox, TabControl, StatusStrip, OpenFileDialog, SaveFileDialog, etc.:
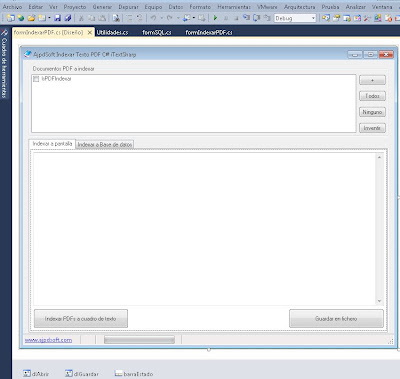
En la pestaña "Indexar a Base de datos" añadiremos estos otros componentes:
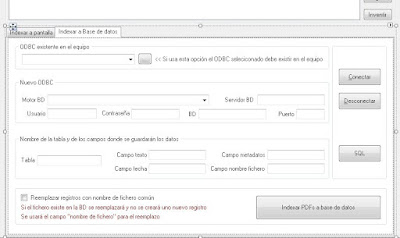
Añadiremos un segundo formulario (Form) a nuestra aplicación, en él mostraremos la consulta SQL necesaria para crear la tabla donde guardar el texto extraído de los ficheros PDF. Para ello pulsaremos en el menú "Proyecto" - "Agregar Windows Forms":
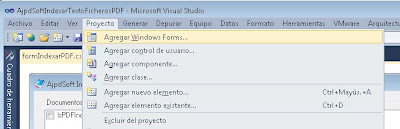
Seleccionaremos "Windows Forms", introduciremos un nombre para el fichero por ejemplo "formSQL.cs" y pulsaremos "Agregar":
En el nuevo formulario agregaremos los siguientes componentes:
Agregaremos también un par de clases, una para las rutinas de cifrado y descrifrado en AES de la contraseña del usuario de la base de datos y otra clase para todas las rutinas restantes: extraer texto PDF, extraer metadatos PDF, insertar registros en base de datos ODBC, obtener lista de orígenes de datos y leer y escribir valores de configuración en fichero .config. Para agregar una nueva clase al proyecto pulsaremos en el menú "Proyecto" - "Agregar clase":

Seleccionaremos "Clase" y escribiremos el nombre del fichero de la clase, por ejemplo "cifrarAES.cs", pulsaremos "Agregar":
Introduciremos el siguiente código Visual C# .Net para la clase "cifrarAES.cs" (cifrarAES):
using System;
using System.Security.Cryptography;
using System.Text;
using System.IO;
namespace AjpdSoftIndexarTextoFicherosPDF
{
class cifrarAES
{
public string cifrarTextoAES (string textoCifrar, string palabraPaso,
string valorRGBSalt, string algoritmoEncriptacionHASH,
int iteraciones, string vectorInicial, int tamanoClave)
{
try
{
byte[] InitialVectorBytes = Encoding.ASCII.GetBytes(vectorInicial);
byte[] saltValueBytes = Encoding.ASCII.GetBytes(valorRGBSalt);
byte[] plainTextBytes = Encoding.UTF8.GetBytes(textoCifrar);
PasswordDeriveBytes password =
new PasswordDeriveBytes(palabraPaso, saltValueBytes,
algoritmoEncriptacionHASH, iteraciones);
byte[] keyBytes = password.GetBytes(tamanoClave / 8);
RijndaelManaged symmetricKey = new RijndaelManaged();
symmetricKey.Mode = CipherMode.CBC;
ICryptoTransform encryptor =
symmetricKey.CreateEncryptor(keyBytes, InitialVectorBytes);
MemoryStream memoryStream = new MemoryStream();
CryptoStream cryptoStream =
new CryptoStream(memoryStream, encryptor, CryptoStreamMode.Write);
cryptoStream.Write(plainTextBytes, 0, plainTextBytes.Length);
cryptoStream.FlushFinalBlock();
byte[] cipherTextBytes = memoryStream.ToArray();
memoryStream.Close();
cryptoStream.Close();
string textoCifradoFinal = Convert.ToBase64String(cipherTextBytes);
return textoCifradoFinal;
}
catch
{
return null;
}
}
public string descifrarTextoAES (string textoCifrado, string palabraPaso,
string valorRGBSalt, string algoritmoEncriptacionHASH,
int iteraciones, string vectorInicial, int tamanoClave)
{
try
{
byte[] InitialVectorBytes = Encoding.ASCII.GetBytes(vectorInicial);
byte[] saltValueBytes = Encoding.ASCII.GetBytes(valorRGBSalt);
byte[] cipherTextBytes = Convert.FromBase64String(textoCifrado);
PasswordDeriveBytes password =
new PasswordDeriveBytes(palabraPaso, saltValueBytes,
algoritmoEncriptacionHASH, iteraciones);
byte[] keyBytes = password.GetBytes(tamanoClave / 8);
RijndaelManaged symmetricKey = new RijndaelManaged();
symmetricKey.Mode = CipherMode.CBC;
ICryptoTransform decryptor =
symmetricKey.CreateDecryptor(keyBytes, InitialVectorBytes);
MemoryStream memoryStream = new MemoryStream(cipherTextBytes);
CryptoStream cryptoStream =
new CryptoStream(memoryStream, decryptor, CryptoStreamMode.Read);
byte[] plainTextBytes = new byte[cipherTextBytes.Length];
int decryptedByteCount =
cryptoStream.Read(plainTextBytes, 0, plainTextBytes.Length);
memoryStream.Close();
cryptoStream.Close();
string textoDescifradoFinal =
Encoding.UTF8.GetString(plainTextBytes, 0, decryptedByteCount);
return textoDescifradoFinal;
}
catch
{
return null;
}
}
}
}
De la misma forma agregaremos una segunda clase que llamaremos "Utilidades.cs":
Introduciremos el siguiente código Visual C# .Net para la clase "Utilidades.cs" (Utilidades):
using System;
using System.Configuration;
using System.Windows.Forms;
using iTextSharp;
using iTextSharp.text;
using iTextSharp.text.pdf;
using iTextSharp.text.pdf.parser;
using System.Collections.Generic;
using System.Text;
using System.IO;
using System.Collections;
using System.Data.Odbc;
using System.Data;
namespace AjpdSoftIndexarTextoFicherosPDF
{
class Utilidades
{
//para tipo de DNS (ODBC)
public enum DataSourceType { System, User }
//para la conexión con la BD ODBC
//para añadir el texto indexado de los PDF
public OdbcConnection conexionBDODBC = new OdbcConnection();
//leer valor del parámetro de configuración en el fichero .config
public string leerValorConfiguracion (string clave)
{
try
{
string resultado =
ConfigurationManager.AppSettings[clave].ToString();
return resultado;
}
catch
{
return "";
}
}
//escribir valor de parámetro de configuración en fichero .config
public void guardarValorConfiguracion(string clave, string valor)
{
try
{
//La línea siguiente no funcionará bien en tiempo de diseño
//pues VC# usa el fichero xxx.vshost.config en la depuración
//Configuration config =
// ConfigurationManager.OpenExeConfiguration(ConfigurationUserLevel.None);
//sí pues la cambiamos por:
Configuration ficheroConfXML =
ConfigurationManager.OpenExeConfiguration(Application.ExecutablePath);
//eliminamos la clave actual (si existe), si no la eliminamos
//los valores se irán acumulando separados por coma
ficheroConfXML.AppSettings.Settings.Remove(clave);
//asignamos el valor en la clave indicada
ficheroConfXML.AppSettings.Settings.Add(clave, valor);
//guardamos los cambios definitivamente en el fichero de configuración
ficheroConfXML.Save(ConfigurationSaveMode.Modified);
}
catch
{
/* MessageBox.Show("Error al guardar valor de configuración: " +
System.Environment.NewLine + System.Environment.NewLine +
ex.GetType().ToString() + System.Environment.NewLine +
ex.Message, "Error",
MessageBoxButtons.OK, MessageBoxIcon.Error);*/
}
}
//obtiene los metadatos del fichero PDF indicado
public string obtenerMetaDatosFicheroPDF(string ficheroPDFIndexar)
{
string mMetadatos = "";
try
{
PdfReader ficheroPDF = new PdfReader(ficheroPDFIndexar);
Dictionary metadatosPDF = ficheroPDF.Info;
foreach (KeyValuePair clavesMetadatosPDF in metadatosPDF)
{
if (mMetadatos != "")
{
mMetadatos = mMetadatos + Environment.NewLine +
(clavesMetadatosPDF.Key + " ===> " + clavesMetadatosPDF.Value);
}
else
{
mMetadatos = (clavesMetadatosPDF.Key + " ===> " +
clavesMetadatosPDF.Value);
}
}
return mMetadatos;
}
catch
{
return null;
}
}
//obtiene el texto del fichero PDF indicado
public string obtenerTextoFicheroPDF(string ficheroPDF)
{
StringBuilder textoPDFIndexado = new StringBuilder();
try
{
if (File.Exists(ficheroPDF))
{
PdfReader pdfReader = new PdfReader(ficheroPDF);
for (int page = 1; page <= pdfReader.NumberOfPages; page++)
{
ITextExtractionStrategy strategy =
new SimpleTextExtractionStrategy();
string currentText =
PdfTextExtractor.GetTextFromPage(pdfReader, page, strategy);
currentText = Encoding.UTF8.GetString(ASCIIEncoding.Convert(
Encoding.Default, Encoding.UTF8,
Encoding.Default.GetBytes(currentText)));
textoPDFIndexado.Append(currentText);
pdfReader.Close();
}
}
return textoPDFIndexado.ToString();
}
catch
{
return null;
}
}
//obtiene todos los data sources (orígenes de datos) del sistema
public System.Collections.SortedList obtenerDataSourcesSistema()
{
System.Collections.SortedList listaODBC = new System.Collections.SortedList();
Microsoft.Win32.RegistryKey reg =
(Microsoft.Win32.Registry.LocalMachine).OpenSubKey("Software");
if (reg != null)
{
reg = reg.OpenSubKey("ODBC");
if (reg != null)
{
reg = reg.OpenSubKey("ODBC.INI");
if (reg != null)
{
reg = reg.OpenSubKey("ODBC Data Sources");
if (reg != null)
{
// Obtener todas las entradas DSN definidas en DSN_LOC_IN_REGISTRY.
foreach (string sName in reg.GetValueNames())
{
listaODBC.Add(sName, DataSourceType.System);
}
}
try
{
reg.Close();
}
catch { /* ignorar un posible error */ }
}
}
}
return listaODBC;
}
//obtiene todos los data sources (orígenes de datos) del usuario
public SortedList obtenerDataSourcesUsuario()
{
SortedList listaODBC = new SortedList();
Microsoft.Win32.RegistryKey reg =
(Microsoft.Win32.Registry.CurrentUser).OpenSubKey("Software");
if (reg != null)
{
reg = reg.OpenSubKey("ODBC");
if (reg != null)
{
reg = reg.OpenSubKey("ODBC.INI");
if (reg != null)
{
reg = reg.OpenSubKey("ODBC Data Sources");
if (reg != null)
{
// Obtener todas las entradas DSN definidas en DSN_LOC_IN_REGISTRY.
foreach (string sName in reg.GetValueNames())
{
listaODBC.Add(sName, DataSourceType.User);
}
}
try
{
reg.Close();
}
catch { /* ignorar un posible error */ }
}
}
}
return listaODBC;
}
public bool existeRegistro(string ficheroPDF,
string campoFicheroPDF, string nombreTabla)
{
try
{
OdbcCommand comandoSQL = conexionBDODBC.CreateCommand();
comandoSQL.CommandText = "select count(*) from " +
nombreTabla + " where " + campoFicheroPDF + " = ?";
OdbcParameter parametroSQL = new OdbcParameter();
parametroSQL.DbType = System.Data.DbType.String;
parametroSQL.Value = ficheroPDF;
comandoSQL.Parameters.Add(parametroSQL);
OdbcDataReader resultadoSQL =
comandoSQL.ExecuteReader(CommandBehavior.CloseConnection);
resultadoSQL.Read();
Int32 numero = resultadoSQL.GetInt32(0);
//resultadoSQL.Close();
return numero > 0;
}
catch (Exception ex)
{
MessageBox.Show("Error de base de datos: " +
System.Environment.NewLine + System.Environment.NewLine +
ex.GetType().ToString() + System.Environment.NewLine +
ex.Message, "Error al crear PDF",
MessageBoxButtons.OK, MessageBoxIcon.Error);
return false;
}
}
//Insertar registro en base de datos ODBC con los datos del PDF indexado
public void insertarRegistroBD (string ficheroPDF, string textoPDF,
string metadatosPDF, string campoFichero, string campoTexto,
string campoMetaDatos, string nombreTabla, string campoFecha,
bool reemplazar)
{
try
{
bool insertar = true;
if (reemplazar)
{
insertar = !existeRegistro(ficheroPDF, campoFichero, nombreTabla);
}
//actualizar registro ya existente
if (!insertar)
{
OdbcCommand comandoSQL = conexionBDODBC.CreateCommand();
comandoSQL.CommandText = "update " + nombreTabla + " set " +
campoTexto + " = ?, " +
campoMetaDatos + " = ?, " +
campoFecha + " = ?" +
" where " + campoFichero + " = ?";
OdbcParameter parametroSQL = new OdbcParameter();
parametroSQL.DbType = System.Data.DbType.String;
parametroSQL.Value = textoPDF;
comandoSQL.Parameters.Add(parametroSQL);
parametroSQL = new OdbcParameter();
parametroSQL.DbType = System.Data.DbType.String;
parametroSQL.Value = metadatosPDF;
comandoSQL.Parameters.Add(parametroSQL);
parametroSQL = new OdbcParameter();
parametroSQL.DbType = System.Data.DbType.Date;
parametroSQL.Value = DateTime.Now;
comandoSQL.Parameters.Add(parametroSQL);
parametroSQL = new OdbcParameter();
parametroSQL.DbType = System.Data.DbType.String;
parametroSQL.Value = ficheroPDF;
comandoSQL.Parameters.Add(parametroSQL);
comandoSQL.ExecuteNonQuery();
}
//insertar nuevo registro
if (insertar)
{
OdbcCommand comandoSQL = conexionBDODBC.CreateCommand();
comandoSQL.CommandText = "insert into " + nombreTabla +
" (" + campoFichero + "," + campoTexto +
"," + campoMetaDatos + ", " + campoFecha +
") values (?, ?, ?, ?)";
OdbcParameter parametroSQL = new OdbcParameter();
parametroSQL.DbType = System.Data.DbType.String;
parametroSQL.Value = ficheroPDF;
comandoSQL.Parameters.Add(parametroSQL);
parametroSQL = new OdbcParameter();
parametroSQL.DbType = System.Data.DbType.String;
parametroSQL.Value = textoPDF;
comandoSQL.Parameters.Add(parametroSQL);
parametroSQL = new OdbcParameter();
parametroSQL.DbType = System.Data.DbType.String;
parametroSQL.Value = metadatosPDF;
comandoSQL.Parameters.Add(parametroSQL);
parametroSQL = new OdbcParameter();
parametroSQL.DbType = System.Data.DbType.Date;
parametroSQL.Value = DateTime.Now;
comandoSQL.Parameters.Add(parametroSQL);
comandoSQL.ExecuteNonQuery();
/*
//Segundo método de inserción SQL con parámetros
OdbcCommand cmd = new OdbcCommand();
cmd.Connection = conexionBDODBC;
cmd.CommandText = "INSERT INTO " + nombreTabla + " (" +
campoFichero + ", " + campoTexto + ", " +
campoMetaDatos + ", " + campoFecha +
" ) VALUES (@ficheroPDF, @textoPDF, @metadatosPDF, @fecha);";
cmd.Parameters.AddWithValue("@ficheroPDF", ficheroPDF);
cmd.Parameters.AddWithValue("@textoPDF", textoPDF);
cmd.Parameters.AddWithValue("@metadatosPDF", metadatosPDF);
cmd.Parameters.AddWithValue("@fecha", DateTime.Now);
cmd.ExecuteNonQuery();
*/
}
}
catch (Exception ex)
{
MessageBox.Show("Error de base de datos: " +
System.Environment.NewLine + System.Environment.NewLine +
ex.GetType().ToString() + System.Environment.NewLine +
ex.Message, "Error al crear PDF",
MessageBoxButtons.OK, MessageBoxIcon.Error);
}
}
}
}
A continuación mostramos el código fuente Visual C# .Net de cada botón y cada evento del formulario principal (formIndexarPDF.cs). Todo el código y la aplicación completa están disponibles gratuitamente en: AjpdSoft Indexar Texto PDF C# iTextSharp:
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.IO;
using System.Collections;
using System.Data.Odbc;
namespace AjpdSoftIndexarTextoFicherosPDF
{
public partial class formIndexarPDF : Form
{
Utilidades util = new Utilidades();
public formIndexarPDF()
{
InitializeComponent();
}
private void btInsertarDocPDFIndexar_Click(object sender, EventArgs e)
{
dlAbrir.CheckFileExists = true;
dlAbrir.CheckPathExists = true;
dlAbrir.Multiselect = true;
dlAbrir.DefaultExt = "pdf";
dlAbrir.FileName = "";
dlAbrir.Filter = "Archivos PDF (*.pdf)|*.pdf|Todos los archivos (*.*)|*.*";
dlAbrir.Title = "Seleccionar fichero PDF a dividir y separar páginas";
if (dlAbrir.ShowDialog() == DialogResult.OK)
{
lsPDFIndexar.Items.AddRange(dlAbrir.FileNames);
for (int i = 0; i < lsPDFIndexar.Items.Count; ++i)
lsPDFIndexar.SetItemChecked(i, true);
}
}
private void btIndexarPDF_Click(object sender, EventArgs e)
{
if (lsPDFIndexar.CheckedItems.Count != 0)
{
string textoIndexadoPDFTodos = "";
string textoIndexadoPDFActual = "";
string ficheroPDFIndexar = "";
string mMetadatos = "";
int numElementos = lsPDFIndexar.CheckedItems.Count;
this.Cursor = Cursors.WaitCursor;
bp.Minimum = 0;
bp.Maximum = numElementos - 1;
bp.Value = 0;
for (int i = 0; i <= lsPDFIndexar.CheckedItems.Count - 1; i++)
{
ficheroPDFIndexar = lsPDFIndexar.CheckedItems[i].ToString();
bp.Value = i;
lInfo.Text = Convert.ToString(i + 1) +
"/" + Convert.ToString(numElementos) +
" [" + Path.GetFileName(ficheroPDFIndexar) + "]";
Application.DoEvents();
//obtener metadatos del fichero PDF
mMetadatos = util.obtenerMetaDatosFicheroPDF(ficheroPDFIndexar);
//obtener el texto del PDF
textoIndexadoPDFActual = util.obtenerTextoFicheroPDF(ficheroPDFIndexar);
if (textoIndexadoPDFTodos != "")
{
textoIndexadoPDFTodos = textoIndexadoPDFTodos +
Environment.NewLine + Environment.NewLine +
"==================================" +
Environment.NewLine + Environment.NewLine +
"Fichero: " + ficheroPDFIndexar + Environment.NewLine +
mMetadatos + Environment.NewLine + textoIndexadoPDFActual;
}
else
{
textoIndexadoPDFTodos =
"Fichero: " + ficheroPDFIndexar + Environment.NewLine +
mMetadatos + Environment.NewLine + textoIndexadoPDFActual;
}
}
txtResultadoIndexacionPDF.Text = textoIndexadoPDFTodos;
this.Cursor = Cursors.Default;
lInfo.Text = "Proceso de indexación de PDF finalizado";
bp.Value = 0;
MessageBox.Show("Proceso de indexación de PDF finalizado correctamente.",
"Fin proceso", MessageBoxButtons.OK, MessageBoxIcon.Information);
}
else
{
btInsertarDocPDFIndexar.Focus();
MessageBox.Show("Debe chequear los ficheros PDF a indexar a pantalla.",
"Seleccionar PDF", MessageBoxButtons.OK, MessageBoxIcon.Information);
}
}
private void btSelTodos_Click(object sender, EventArgs e)
{
for (int i = 0; i < lsPDFIndexar.Items.Count; i++)
{
lsPDFIndexar.SetItemChecked(i, true);
}
}
private void btNinguno_Click(object sender, EventArgs e)
{
for (int i = 0; i < lsPDFIndexar.Items.Count; i++)
{
lsPDFIndexar.SetItemChecked(i, false);
}
}
private void btInvertir_Click(object sender, EventArgs e)
{
for (int i = 0; i < lsPDFIndexar.Items.Count; i++)
{
lsPDFIndexar.SetItemChecked(i, ! lsPDFIndexar.GetItemChecked(i));
}
}
private void bConectar_Click(object sender, EventArgs e)
{
if (txtTabla.Text != "")
{
try
{
if (lsODBC.Text != "")
{
util.conexionBDODBC = new OdbcConnection("dsn=" + lsODBC.Text +
";UID=" + txtUsuario.Text + ";PWD=" + txtContrasena.Text + ";");
}
else
{
if (txtPuerto.Text != "")
{
util.conexionBDODBC = new OdbcConnection("DRIVER={" + lsMotor.Text +
"};SERVER=" + txtServidor.Text + "; PORT=" + txtPuerto.Text +
";UID=" + txtUsuario.Text +
";PWD=" + txtContrasena.Text + ";" +
";DATABASE=" + txtBD.Text + ";");
}
else
{
util.conexionBDODBC = new OdbcConnection("DRIVER={" + lsMotor.Text +
"};SERVER=" + txtServidor.Text + ";UID=" + txtUsuario.Text +
";PWD=" + txtContrasena.Text + ";" +
";DATABASE=" + txtBD.Text + ";");
}
}
util.conexionBDODBC.Open();
if (util.conexionBDODBC.State == ConnectionState.Open)
{
bDesconectar.Enabled = true;
bConectar.Enabled = false;
OdbcCommand comandoSQL;
string consultaSQL;
consultaSQL = "Select count(*) from " + txtTabla.Text;
try
{
comandoSQL = new OdbcCommand(consultaSQL, util.conexionBDODBC);
int numeroRegistros = Convert.ToInt32(comandoSQL.ExecuteScalar());
MessageBox.Show("La tabla " + txtTabla.Text + " existe con " +
Convert.ToString(numeroRegistros) + " registros.", "Conexión BD",
MessageBoxButtons.OK, MessageBoxIcon.Information);
beConectadoBD.Text = "Conectado a BD";
bDesconectar.Enabled = true;
bConectar.Enabled = false;
}
catch (Exception ex)
{
util.conexionBDODBC.Close();
bDesconectar.Enabled = false;
bConectar.Enabled = true;
MessageBox.Show("Error al ejecutar SQL: " +
System.Environment.NewLine + System.Environment.NewLine +
ex.GetType().ToString() + System.Environment.NewLine +
ex.Message, "Error",
MessageBoxButtons.OK, MessageBoxIcon.Error);
}
}
else
{
beConectadoBD.Text = "No conectado a BD";
bDesconectar.Enabled = false;
bConectar.Enabled = true;
MessageBox.Show("No conectado a la base de datos.", "Conexión BD",
MessageBoxButtons.OK, MessageBoxIcon.Exclamation);
}
}
catch (Exception error)
{
bDesconectar.Enabled = false;
bConectar.Enabled = true;
beConectadoBD.Text = "No conectado a BD";
util.conexionBDODBC.Close();
MessageBox.Show("Error de base de datos: " +
System.Environment.NewLine + System.Environment.NewLine +
error.GetType().ToString() + System.Environment.NewLine +
error.Message, "Error al crear PDF",
MessageBoxButtons.OK, MessageBoxIcon.Error);
}
}
else
{
MessageBox.Show("Debe indicar el nombre de la tabla de " +
"la BD donde se crearán los registros " +
"con el indexado del los PDF.", "Tabla",
MessageBoxButtons.OK, MessageBoxIcon.Exclamation);
txtTabla.Focus();
}
}
private void btListaODBC_Click(object sender, EventArgs e)
{
SortedList listaODBC = new System.Collections.SortedList();
lsODBC.Items.Clear();
listaODBC = util.obtenerDataSourcesSistema();
foreach (DictionaryEntry key in listaODBC)
{
lsODBC.Items.Add(key.Key.ToString());
}
listaODBC = util.obtenerDataSourcesUsuario();
foreach (DictionaryEntry key in listaODBC)
{
lsODBC.Items.Add(key.Key.ToString());
}
}
private void btGuardarTextoFichero_Click(object sender, EventArgs e)
{
dlGuardar.Title = "Selección de carpeta y fichero de " +
"texto donde se guardará la indexación";
dlGuardar.Filter = "Texto (*.txt)|*.txt|Todos los ficheros (*.*)|*.*";
dlGuardar.DefaultExt = "txt";
dlGuardar.FilterIndex = 1;
dlGuardar.CheckFileExists = false;
dlGuardar.OverwritePrompt = true;
if (dlGuardar.ShowDialog() == DialogResult.OK)
{
try
{
StreamWriter ficheroTexto = new StreamWriter(dlGuardar.FileName,
false, System.Text.Encoding.Default);
ficheroTexto.Write(txtResultadoIndexacionPDF.Text);
ficheroTexto.Flush();
ficheroTexto.Close();
MessageBox.Show("Fichero de texto guardado correctamente.",
"Fichero guardado",
MessageBoxButtons.OK, MessageBoxIcon.Information);
}
catch (Exception ex)
{
MessageBox.Show("Error al guardar fichero de texto: " +
System.Environment.NewLine + System.Environment.NewLine +
ex.GetType().ToString() + System.Environment.NewLine +
ex.Message, "Error",
MessageBoxButtons.OK, MessageBoxIcon.Error);
}
}
}
private void bDesconectar_Click(object sender, EventArgs e)
{
try
{
util.conexionBDODBC.Close();
bDesconectar.Enabled = false;
bConectar.Enabled = true;
beConectadoBD.Text = "No conectado a BD";
bConectar.Focus();
}
catch (Exception error)
{
bDesconectar.Enabled = false;
bConectar.Enabled = true;
MessageBox.Show("Error de base de datos: " +
System.Environment.NewLine + System.Environment.NewLine +
error.GetType().ToString() + System.Environment.NewLine +
error.Message, "Error al crear PDF",
MessageBoxButtons.OK, MessageBoxIcon.Error);
}
}
private void btIndexarPDFBD_Click(object sender, EventArgs e)
{
if (util.conexionBDODBC.State == ConnectionState.Open)
{
if (lsPDFIndexar.CheckedItems.Count != 0)
{
string textoIndexadoPDF = "";
string ficheroPDFIndexar = "";
string mMetadatos = "";
int numElementos = lsPDFIndexar.CheckedItems.Count;
this.Cursor = Cursors.WaitCursor;
bp.Minimum = 0;
bp.Maximum = numElementos - 1;
bp.Value = 0;
for (int i = 0; i <= numElementos - 1; i++)
{
bp.Value = i;
ficheroPDFIndexar = lsPDFIndexar.CheckedItems[i].ToString();
lInfo.Text = Convert.ToString(i + 1) +
"/" + Convert.ToString(numElementos) +
" [" + Path.GetFileName (ficheroPDFIndexar) + "]";
Application.DoEvents();
//Obtener metadatos del fichero PDF
mMetadatos = util.obtenerMetaDatosFicheroPDF(ficheroPDFIndexar);
//obtener texto indexado del PDF
textoIndexadoPDF = util.obtenerTextoFicheroPDF(ficheroPDFIndexar);
util.insertarRegistroBD(ficheroPDFIndexar, textoIndexadoPDF,
mMetadatos, txtCampoFicheroPDF.Text,
txtCampoTextoPDF.Text, txtCampoMetadatosPDF.Text,
txtTabla.Text, txtCampoFecha.Text, opBDIndexarReemplazar.Checked);
}
this.Cursor = Cursors.Default;
lInfo.Text = "Proceso de indexación de PDF finalizado";
bp.Value = 0;
util.conexionBDODBC.Close();
bConectar.Enabled = true;
bDesconectar.Enabled = false;
beConectadoBD.Text = "No conectado a BD";
MessageBox.Show("Proceso de indexación de PDF finalizado correctamente.",
"Fin proceso", MessageBoxButtons.OK, MessageBoxIcon.Information);
}
else
{
btInsertarDocPDFIndexar.Focus();
MessageBox.Show("Debe chequear los ficheros PDF a indexar a base de datos.",
"Seleccionar PDF", MessageBoxButtons.OK, MessageBoxIcon.Information);
}
}
else
{
MessageBox.Show("Debe estar conectado a la base de datos para " +
"realizar la indexación de los ficheros PDF seleccionados.",
"Error al crear PDF", MessageBoxButtons.OK, MessageBoxIcon.Information);
}
}
private void formIndexarPDF_FormClosed(object sender, FormClosedEventArgs e)
{
Utilidades proUtilidades = new Utilidades();
cifrarAES cifradoAES = new cifrarAES();
proUtilidades.guardarValorConfiguracion("BD.ODBC", lsODBC.Text);
proUtilidades.guardarValorConfiguracion("BD.Motor", lsMotor.Text);
proUtilidades.guardarValorConfiguracion("BD.Servidor", txtServidor.Text);
proUtilidades.guardarValorConfiguracion("BD.Usuario", txtUsuario.Text);
proUtilidades.guardarValorConfiguracion("BD.Contraseña",
cifradoAES.cifrarTextoAES (txtContrasena.Text,
"AjpdSoft_Frase_Encriptado", "AjpdSoft_Frase_Encriptado",
"MD5", 22, "1234567891234567", 128));
proUtilidades.guardarValorConfiguracion("BD.Base_Datos", txtBD.Text);
proUtilidades.guardarValorConfiguracion("BD.Puerto", txtPuerto.Text);
proUtilidades.guardarValorConfiguracion("BD.Tabla", txtTabla.Text);
proUtilidades.guardarValorConfiguracion("BD.Campo_Texto_Indexado",
txtCampoTextoPDF.Text);
proUtilidades.guardarValorConfiguracion("BD.Campo_Fecha",
txtCampoFecha.Text);
proUtilidades.guardarValorConfiguracion("BD.Campo_Metadatos",
txtCampoMetadatosPDF.Text);
proUtilidades.guardarValorConfiguracion("BD.Campo_Fichero_PDF",
txtCampoFicheroPDF.Text);
}
private void btSQL_Click(object sender, EventArgs e)
{
formSQL frmSQL = new formSQL();
frmSQL.ShowDialog();
}
private void formIndexarPDF_Load(object sender, EventArgs e)
{
Utilidades proUtilidades = new Utilidades();
cifrarAES cifradoAES = new cifrarAES();
lsODBC.Text =
proUtilidades.leerValorConfiguracion("BD.ODBC");
lsMotor.Text =
proUtilidades.leerValorConfiguracion("BD.Motor");
txtServidor.Text =
proUtilidades.leerValorConfiguracion("BD.Servidor");
txtUsuario.Text =
proUtilidades.leerValorConfiguracion("BD.Usuario");
txtContrasena.Text =
cifradoAES.descifrarTextoAES(
proUtilidades.leerValorConfiguracion("BD.Contraseña"),
"AjpdSoft_Frase_Encriptado", "AjpdSoft_Frase_Encriptado",
"MD5", 22, "1234567891234567", 128);
txtBD.Text =
proUtilidades.leerValorConfiguracion("BD.Base_Datos");
txtPuerto.Text =
proUtilidades.leerValorConfiguracion("BD.Puerto");
txtTabla.Text=
proUtilidades.leerValorConfiguracion("BD.Tabla");
txtCampoTextoPDF.Text =
proUtilidades.leerValorConfiguracion("BD.Campo_Texto_Indexado");
txtCampoFecha.Text =
proUtilidades.leerValorConfiguracion("BD.Campo_Fecha");
txtCampoMetadatosPDF.Text =
proUtilidades.leerValorConfiguracion("BD.Campo_Metadatos");
txtCampoFicheroPDF.Text =
proUtilidades.leerValorConfiguracion("BD.Campo_Fichero_PDF");
}
private void toolStripStatusLabel1_Click_1(object sender, EventArgs e)
{
//abrir navegador por defecto y acceder a la URL www.ajpdsoft.com
System.Diagnostics.Process.Start("http://www.ajpdsoft.com");
}
}
}
El formulario "formSQL.cs" contendrá el siguiente código Visual C# .Net:
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
namespace AjpdSoftIndexarTextoFicherosPDF
{
public partial class formSQL : Form
{
public formSQL()
{
InitializeComponent();
}
private void formSQL_FormClosed(object sender, FormClosedEventArgs e)
{
this.Dispose();
}
private void btCerrar_Click(object sender, EventArgs e)
{
this.Close();
}
private void btCopiarPortapapeles_Click(object sender, EventArgs e)
{
try
{
Clipboard.SetDataObject(txtSQL.SelectedText, true);
MessageBox.Show("Texto copiado al portapapeles de Windows.",
"Copiado", MessageBoxButtons.OK, MessageBoxIcon.Information);
}
catch (Exception err)
{
MessageBox.Show("Error al copiar texto al portapapeles: " +
Environment.NewLine + err.Message, "Error al copiar",
MessageBoxButtons.OK, MessageBoxIcon.Error);
}
}
}
}
AjpdSoft Indexar Texto PDF C# iTextSharp
AjpdSoft Indexar Texto PDF C# iTextSharp permite extraer el texto y los metadatos de los ficheros PDF seleccionados y guardarlo en la tabla de una base de datos.
AjpdSoft Indexar Texto PDF C# iTextSharp no necesita usar ningún software de terceros, únicamente usa la librería gratuita iTextSharp.dll.
A continuación explicamos cómo funciona la aplicación AjpdSoft Indexar Texto PDF C# iTextSharp. La aplicación permite dos opciones de indexación o extracción de texto y metadatos de ficheros PDF, o bien mostrándolo en pantalla o bien guardándolo en base de datos. Para la primera opción, pulsaremos en el botón "+" para seleccionar los ficheros PDF que queramos indexar (permite selección de múltiples ficheros en la misma o diferentes carpetas):
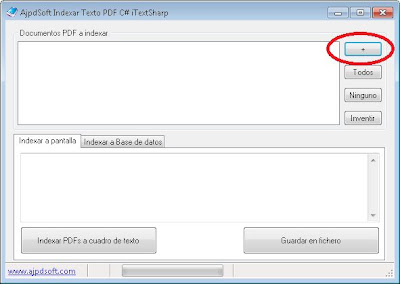
Seleccionaremos los ficheros PDF a indexar:

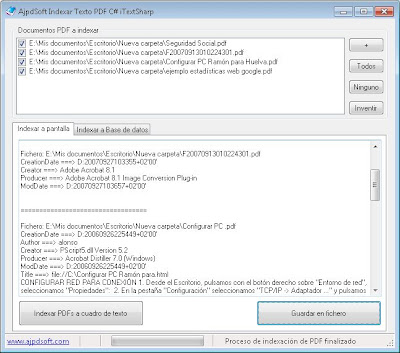
Para extraer el texto y los metadatos de todos los ficheros PDF chequeados y mostrarlo en pantalla pulsaremos "Indexar PDFs a cuadro de texto":

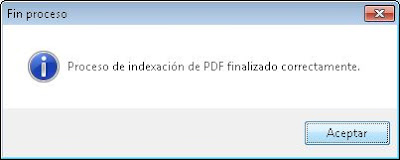
La aplicación mostrará el progreso del proceso en la barra de estado, indicando el fichero PDF actual, los que va a indexar y una barra de progreso. Cuando el proceso de indexación concluya mostrará un mensaje como el siguiente "Proceso de indexación de PDF finalizado correctamente":
Desde el cuadro de texto podremos copiar el texto extraído de los ficheros PDF al portapapeles o bien guardarlo desde la aplicación en fichero de texto pulsando en "Guardar en fichero":
La segunda posibilidad que presenta la aplicación es guardar los datos extraídos de los ficheros PDF en una tabla de una base de datos ODBC. Si hemos configurado un servidor de base de datos que soporte ODBC y hemos creado la tabla correspondiente como indicamos aquí podremos configurar AjpdSoft Indexar Texto PDF C# iTextSharp para guardar los datos obtenidos en una base de datos.
Para guardar los datos indexados de los PDF en una base de datos, la aplicación AjpdSoft Indexar Texto PDF C# iTextSharp permite dos opciones de conexión:
1. Si ya tenemos un origen de datos ODBC creado en el equipo podremos seleccionarlo (o escribirlo) en "ODBC existente en el equipo", usando esta opción no tendremos que introducir ningún dato más pues todos los datos se establecen en el origen de datos, como indicamos aquí:

Si optamos por esta opción, como decimos, no habrá que introducir más datos para la conexión con la base de datos.
2. La segunda posibilidad es dejar en blanco el campo anterior (ODBC existente en el equipo) e introducir los datos de conexión en "Nuevo ODBC". Si elegimos esta opción tendremos la ventaja de que no hay que crear ningún origen de datos en el equipo, directamente AjpdSoft Indexar Texto PDF C# iTextSharp usará los siguientes datos para establecer la conexión:
- Motor BD: nombre exacto del origen de datos ODBC, en el desplegable aparecen un listado de los nombres "típicos", pero pueden variar en función de las versiones instaladas de cada controlador de cada motor de base de datos. En nuestro caso usaremos "PostgreSQL ANSI".
- Servidor BD: IP o hostname del equipo con la base de datos instalada, en nuestro caso "pcajpdsoft".
- Usuario: nombre de usuario del motor de base de datos con permisos suficientes para insertar registros en la tabla indicada.
- Contraseña: contraseña del usuario de la base de datos.
- BD: nombre de la base de datos a la que nos conectaremos, en nuestro ejemplo "indexadopdf".
- Puerto: podemos dejarlo en blanco para usar el puerto por defecto del motor de base de datos elegido o bien especificar uno si es diferente al de defecto.

Una vez elegido el método de conexión (ODBC existente o bien ODBC nuevo) introduciremos los datos para la tabla de la base de datos:
- Tabla: nombre de la tabla de la base de datos donde guardaremos el texto extraído de los ficheros PDF.
- Campo texto: nombre del campo de la tabla donde se guardará el texto obtenido del fichero PDF.
- Campo metadatos: nombre del campo de la tabla donde se guardarán los metadatos obtenidos del fichero PDF.
- Campo fecha: nombre del campo de la tabla donde se guardará la fecha actual, la fecha en la que se realiza la indexación.
- Campo nombre fichero: nombre del campo de la tabla donde se guardará la ruta y el nombre del fichero PDF indexado.

A continuación pulsaremos en "Conectar" para comprobar la conexión a la base de datos y la existencia de la tabla indicada:
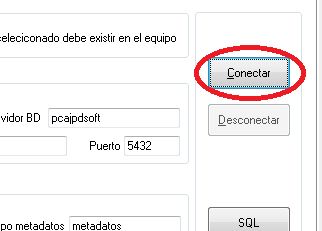
Si todo es correcto la aplicación AjpdSoft Indexar Texto PDF C# iTextSharp mostrará el mensaje "La tabla indexpdf" existe con xxx registros". Si hay algún error en la conexión o falta algún dato la aplicación mostrará el error:

Por último, una vez establecido el método de conexión y los datos de la tabla de la base de datos podremos marcar la opción "Reemplazar registros con nombre de fichero común" para que la aplicación AjpdSoft Indexar Texto PDF C# iTextSharp, antes de insertar un nuevo registro en la tabla, compruebe si ya existe usando la carpeta y el nombre del fichero PDF previamente indexado. Si existe se actualizará y si no existe se creará un nuevo registro. Si no marcamos esta opción siempre se añadirá un nuevo registro sin realizar comprobación previa de su existencia. Tras seleccionar el método de reemplazo pulsaremos en "Indexar PDFs a base de datos" para iniciar el proceso definitivo:

La aplicación AjpdSoft Indexar Texto PDF C# iTextSharp mostrará el progreso del proceso de indexación con una barra de progreso e indicando los ficheros indexados y los que quedan por indexar, todo ello lo mostrará en la barra de tareas:

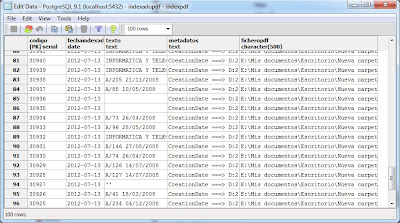
Una vez finalizado el proceso podremos acceder usando cualquier software de consulta de SQL al motor de base de datos que hayamos elegido como destino de la indexación para consultar y buscar los datos de los ficheros PDF:
Código fuente completo de AjpdSoft Indexar Texto PDF C# iTextSharp
A continuación mostramos el enlace para descargar gratuitamente el código fuente completo de la aplicación AjpdSoft Indexar Texto PDF C# iTextSharp desarrollada con Visual C# .Net 2010 (de Microsoft Studio .Net 2010):
El listado completo del código fuente de la aplicación AjpdSoft Indexar Texto PDF C# iTextSharp:
- Código para "cifrarAES.cs" (clase para cifrado de texto en AES):
using System;
using System.Security.Cryptography;
using System.Text;
using System.IO;
namespace AjpdSoftIndexarTextoFicherosPDF
{
class cifrarAES
{
public string cifrarTextoAES (string textoCifrar, string palabraPaso,
string valorRGBSalt, string algoritmoEncriptacionHASH,
int iteraciones, string vectorInicial, int tamanoClave)
{
try
{
byte[] InitialVectorBytes = Encoding.ASCII.GetBytes(vectorInicial);
byte[] saltValueBytes = Encoding.ASCII.GetBytes(valorRGBSalt);
byte[] plainTextBytes = Encoding.UTF8.GetBytes(textoCifrar);
PasswordDeriveBytes password =
new PasswordDeriveBytes(palabraPaso, saltValueBytes,
algoritmoEncriptacionHASH, iteraciones);
byte[] keyBytes = password.GetBytes(tamanoClave / 8);
RijndaelManaged symmetricKey = new RijndaelManaged();
symmetricKey.Mode = CipherMode.CBC;
ICryptoTransform encryptor =
symmetricKey.CreateEncryptor(keyBytes, InitialVectorBytes);
MemoryStream memoryStream = new MemoryStream();
CryptoStream cryptoStream =
new CryptoStream(memoryStream, encryptor, CryptoStreamMode.Write);
cryptoStream.Write(plainTextBytes, 0, plainTextBytes.Length);
cryptoStream.FlushFinalBlock();
byte[] cipherTextBytes = memoryStream.ToArray();
memoryStream.Close();
cryptoStream.Close();
string textoCifradoFinal = Convert.ToBase64String(cipherTextBytes);
return textoCifradoFinal;
}
catch
{
return null;
}
}
public string descifrarTextoAES (string textoCifrado, string palabraPaso,
string valorRGBSalt, string algoritmoEncriptacionHASH,
int iteraciones, string vectorInicial, int tamanoClave)
{
try
{
byte[] InitialVectorBytes = Encoding.ASCII.GetBytes(vectorInicial);
byte[] saltValueBytes = Encoding.ASCII.GetBytes(valorRGBSalt);
byte[] cipherTextBytes = Convert.FromBase64String(textoCifrado);
PasswordDeriveBytes password =
new PasswordDeriveBytes(palabraPaso, saltValueBytes,
algoritmoEncriptacionHASH, iteraciones);
byte[] keyBytes = password.GetBytes(tamanoClave / 8);
RijndaelManaged symmetricKey = new RijndaelManaged();
symmetricKey.Mode = CipherMode.CBC;
ICryptoTransform decryptor =
symmetricKey.CreateDecryptor(keyBytes, InitialVectorBytes);
MemoryStream memoryStream = new MemoryStream(cipherTextBytes);
CryptoStream cryptoStream =
new CryptoStream(memoryStream, decryptor, CryptoStreamMode.Read);
byte[] plainTextBytes = new byte[cipherTextBytes.Length];
int decryptedByteCount =
cryptoStream.Read(plainTextBytes, 0, plainTextBytes.Length);
memoryStream.Close();
cryptoStream.Close();
string textoDescifradoFinal =
Encoding.UTF8.GetString(plainTextBytes, 0, decryptedByteCount);
return textoDescifradoFinal;
}
catch
{
return null;
}
}
}
}
-
Código para la clase "Utilidades.cs" (acceso a base de datos, obtención de lista de ODBC, inserción de registros en BD, indexación de texto PDF, extracción de metadatos PDF, leer y guardar valores de configuración:
using System;
using System.Configuration;
using System.Windows.Forms;
using iTextSharp;
using iTextSharp.text;
using iTextSharp.text.pdf;
using iTextSharp.text.pdf.parser;
using System.Collections.Generic;
using System.Text;
using System.IO;
using System.Collections;
using System.Data.Odbc;
using System.Data;
namespace AjpdSoftIndexarTextoFicherosPDF
{
class Utilidades
{
//para tipo de DNS (ODBC)
public enum DataSourceType { System, User }
//para la conexión con la BD ODBC
//para añadir el texto indexado de los PDF
public OdbcConnection conexionBDODBC = new OdbcConnection();
//leer valor del parámetro de configuración en el fichero .config
public string leerValorConfiguracion (string clave)
{
try
{
string resultado =
ConfigurationManager.AppSettings[clave].ToString();
return resultado;
}
catch
{
return "";
}
}
//escribir valor de parámetro de configuración en fichero .config
public void guardarValorConfiguracion(string clave, string valor)
{
try
{
//La línea siguiente no funcionará bien en tiempo de diseño
//pues VC# usa el fichero xxx.vshost.config en la depuración
//Configuration config =
// ConfigurationManager.OpenExeConfiguration(ConfigurationUserLevel.None);
//sí pues la cambiamos por:
Configuration ficheroConfXML =
ConfigurationManager.OpenExeConfiguration(Application.ExecutablePath);
//eliminamos la clave actual (si existe), si no la eliminamos
//los valores se irán acumulando separados por coma
ficheroConfXML.AppSettings.Settings.Remove(clave);
//asignamos el valor en la clave indicada
ficheroConfXML.AppSettings.Settings.Add(clave, valor);
//guardamos los cambios definitivamente en el fichero de configuración
ficheroConfXML.Save(ConfigurationSaveMode.Modified);
}
catch
{
/* MessageBox.Show("Error al guardar valor de configuración: " +
System.Environment.NewLine + System.Environment.NewLine +
ex.GetType().ToString() + System.Environment.NewLine +
ex.Message, "Error",
MessageBoxButtons.OK, MessageBoxIcon.Error);*/
}
}
//obtiene los metadatos del fichero PDF indicado
public string obtenerMetaDatosFicheroPDF(string ficheroPDFIndexar)
{
string mMetadatos = "";
try
{
PdfReader ficheroPDF = new PdfReader(ficheroPDFIndexar);
Dictionary metadatosPDF = ficheroPDF.Info;
foreach (KeyValuePair clavesMetadatosPDF in metadatosPDF)
{
if (mMetadatos != "")
{
mMetadatos = mMetadatos + Environment.NewLine +
(clavesMetadatosPDF.Key + " ===> " + clavesMetadatosPDF.Value);
}
else
{
mMetadatos = (clavesMetadatosPDF.Key + " ===> " +
clavesMetadatosPDF.Value);
}
}
return mMetadatos;
}
catch
{
return null;
}
}
//obtiene el texto del fichero PDF indicado
public string obtenerTextoFicheroPDF(string ficheroPDF)
{
StringBuilder textoPDFIndexado = new StringBuilder();
try
{
if (File.Exists(ficheroPDF))
{
PdfReader pdfReader = new PdfReader(ficheroPDF);
for (int page = 1; page <= pdfReader.NumberOfPages; page++)
{
ITextExtractionStrategy strategy =
new SimpleTextExtractionStrategy();
string currentText =
PdfTextExtractor.GetTextFromPage(pdfReader, page, strategy);
currentText = Encoding.UTF8.GetString(ASCIIEncoding.Convert(
Encoding.Default, Encoding.UTF8,
Encoding.Default.GetBytes(currentText)));
textoPDFIndexado.Append(currentText);
pdfReader.Close();
}
}
return textoPDFIndexado.ToString();
}
catch
{
return null;
}
}
//obtiene todos los data sources (orígenes de datos) del sistema
public System.Collections.SortedList obtenerDataSourcesSistema()
{
System.Collections.SortedList listaODBC = new System.Collections.SortedList();
Microsoft.Win32.RegistryKey reg =
(Microsoft.Win32.Registry.LocalMachine).OpenSubKey("Software");
if (reg != null)
{
reg = reg.OpenSubKey("ODBC");
if (reg != null)
{
reg = reg.OpenSubKey("ODBC.INI");
if (reg != null)
{
reg = reg.OpenSubKey("ODBC Data Sources");
if (reg != null)
{
// Obtener todas las entradas DSN definidas en DSN_LOC_IN_REGISTRY.
foreach (string sName in reg.GetValueNames())
{
listaODBC.Add(sName, DataSourceType.System);
}
}
try
{
reg.Close();
}
catch { /* ignorar un posible error */ }
}
}
}
return listaODBC;
}
//obtiene todos los data sources (orígenes de datos) del usuario
public SortedList obtenerDataSourcesUsuario()
{
SortedList listaODBC = new SortedList();
Microsoft.Win32.RegistryKey reg =
(Microsoft.Win32.Registry.CurrentUser).OpenSubKey("Software");
if (reg != null)
{
reg = reg.OpenSubKey("ODBC");
if (reg != null)
{
reg = reg.OpenSubKey("ODBC.INI");
if (reg != null)
{
reg = reg.OpenSubKey("ODBC Data Sources");
if (reg != null)
{
// Obtener todas las entradas DSN definidas en DSN_LOC_IN_REGISTRY.
foreach (string sName in reg.GetValueNames())
{
listaODBC.Add(sName, DataSourceType.User);
}
}
try
{
reg.Close();
}
catch { /* ignorar un posible error */ }
}
}
}
return listaODBC;
}
public bool existeRegistro(string ficheroPDF,
string campoFicheroPDF, string nombreTabla)
{
try
{
OdbcCommand comandoSQL = conexionBDODBC.CreateCommand();
comandoSQL.CommandText = "select count(*) from " +
nombreTabla + " where " + campoFicheroPDF + " = ?";
OdbcParameter parametroSQL = new OdbcParameter();
parametroSQL.DbType = System.Data.DbType.String;
parametroSQL.Value = ficheroPDF;
comandoSQL.Parameters.Add(parametroSQL);
OdbcDataReader resultadoSQL =
comandoSQL.ExecuteReader(CommandBehavior.CloseConnection);
resultadoSQL.Read();
Int32 numero = resultadoSQL.GetInt32(0);
//resultadoSQL.Close();
return numero > 0;
}
catch (Exception ex)
{
MessageBox.Show("Error de base de datos: " +
System.Environment.NewLine + System.Environment.NewLine +
ex.GetType().ToString() + System.Environment.NewLine +
ex.Message, "Error al crear PDF",
MessageBoxButtons.OK, MessageBoxIcon.Error);
return false;
}
}
//Insertar registro en base de datos ODBC con los datos del PDF indexado
public void insertarRegistroBD (string ficheroPDF, string textoPDF,
string metadatosPDF, string campoFichero, string campoTexto,
string campoMetaDatos, string nombreTabla, string campoFecha,
bool reemplazar)
{
try
{
bool insertar = true;
if (reemplazar)
{
insertar = !existeRegistro(ficheroPDF, campoFichero, nombreTabla);
}
//actualizar registro ya existente
if (!insertar)
{
OdbcCommand comandoSQL = conexionBDODBC.CreateCommand();
comandoSQL.CommandText = "update " + nombreTabla + " set " +
campoTexto + " = ?, " +
campoMetaDatos + " = ?, " +
campoFecha + " = ?" +
" where " + campoFichero + " = ?";
OdbcParameter parametroSQL = new OdbcParameter();
parametroSQL.DbType = System.Data.DbType.String;
parametroSQL.Value = textoPDF;
comandoSQL.Parameters.Add(parametroSQL);
parametroSQL = new OdbcParameter();
parametroSQL.DbType = System.Data.DbType.String;
parametroSQL.Value = metadatosPDF;
comandoSQL.Parameters.Add(parametroSQL);
parametroSQL = new OdbcParameter();
parametroSQL.DbType = System.Data.DbType.Date;
parametroSQL.Value = DateTime.Now;
comandoSQL.Parameters.Add(parametroSQL);
parametroSQL = new OdbcParameter();
parametroSQL.DbType = System.Data.DbType.String;
parametroSQL.Value = ficheroPDF;
comandoSQL.Parameters.Add(parametroSQL);
comandoSQL.ExecuteNonQuery();
}
//insertar nuevo registro
if (insertar)
{
OdbcCommand comandoSQL = conexionBDODBC.CreateCommand();
comandoSQL.CommandText = "insert into " + nombreTabla +
" (" + campoFichero + "," + campoTexto +
"," + campoMetaDatos + ", " + campoFecha +
") values (?, ?, ?, ?)";
OdbcParameter parametroSQL = new OdbcParameter();
parametroSQL.DbType = System.Data.DbType.String;
parametroSQL.Value = ficheroPDF;
comandoSQL.Parameters.Add(parametroSQL);
parametroSQL = new OdbcParameter();
parametroSQL.DbType = System.Data.DbType.String;
parametroSQL.Value = textoPDF;
comandoSQL.Parameters.Add(parametroSQL);
parametroSQL = new OdbcParameter();
parametroSQL.DbType = System.Data.DbType.String;
parametroSQL.Value = metadatosPDF;
comandoSQL.Parameters.Add(parametroSQL);
parametroSQL = new OdbcParameter();
parametroSQL.DbType = System.Data.DbType.Date;
parametroSQL.Value = DateTime.Now;
comandoSQL.Parameters.Add(parametroSQL);
comandoSQL.ExecuteNonQuery();
/*
//Segundo método de inserción SQL con parámetros
OdbcCommand cmd = new OdbcCommand();
cmd.Connection = conexionBDODBC;
cmd.CommandText = "INSERT INTO " + nombreTabla + " (" +
campoFichero + ", " + campoTexto + ", " +
campoMetaDatos + ", " + campoFecha +
" ) VALUES (@ficheroPDF, @textoPDF, @metadatosPDF, @fecha);";
cmd.Parameters.AddWithValue("@ficheroPDF", ficheroPDF);
cmd.Parameters.AddWithValue("@textoPDF", textoPDF);
cmd.Parameters.AddWithValue("@metadatosPDF", metadatosPDF);
cmd.Parameters.AddWithValue("@fecha", DateTime.Now);
cmd.ExecuteNonQuery();
*/
}
}
catch (Exception ex)
{
MessageBox.Show("Error de base de datos: " +
System.Environment.NewLine + System.Environment.NewLine +
ex.GetType().ToString() + System.Environment.NewLine +
ex.Message, "Error al crear PDF",
MessageBoxButtons.OK, MessageBoxIcon.Error);
}
}
}
}
- Formulario "formSQL.cs" (muestra consulta SQL para crear tabla para indexación de texto de PDF) :
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
namespace AjpdSoftIndexarTextoFicherosPDF
{
public partial class formSQL : Form
{
public formSQL()
{
InitializeComponent();
}
private void formSQL_FormClosed(object sender, FormClosedEventArgs e)
{
this.Dispose();
}
private void btCerrar_Click(object sender, EventArgs e)
{
this.Close();
}
private void btCopiarPortapapeles_Click(object sender, EventArgs e)
{
try
{
Clipboard.SetDataObject(txtSQL.SelectedText, true);
MessageBox.Show("Texto copiado al portapapeles de Windows.",
"Copiado", MessageBoxButtons.OK, MessageBoxIcon.Information);
}
catch (Exception err)
{
MessageBox.Show("Error al copiar texto al portapapeles: " +
Environment.NewLine + err.Message, "Error al copiar",
MessageBoxButtons.OK, MessageBoxIcon.Error);
}
}
}
}
- Formulario "formIndexarPDF.cs":
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.IO;
using System.Collections;
using System.Data.Odbc;
namespace AjpdSoftIndexarTextoFicherosPDF
{
public partial class formIndexarPDF : Form
{
Utilidades util = new Utilidades();
public formIndexarPDF()
{
InitializeComponent();
}
private void btInsertarDocPDFIndexar_Click(object sender, EventArgs e)
{
dlAbrir.CheckFileExists = true;
dlAbrir.CheckPathExists = true;
dlAbrir.Multiselect = true;
dlAbrir.DefaultExt = "pdf";
dlAbrir.FileName = "";
dlAbrir.Filter = "Archivos PDF (*.pdf)|*.pdf|Todos los archivos (*.*)|*.*";
dlAbrir.Title = "Seleccionar fichero PDF a dividir y separar páginas";
if (dlAbrir.ShowDialog() == DialogResult.OK)
{
lsPDFIndexar.Items.AddRange(dlAbrir.FileNames);
for (int i = 0; i < lsPDFIndexar.Items.Count; ++i)
lsPDFIndexar.SetItemChecked(i, true);
}
}
private void btIndexarPDF_Click(object sender, EventArgs e)
{
if (lsPDFIndexar.CheckedItems.Count != 0)
{
string textoIndexadoPDFTodos = "";
string textoIndexadoPDFActual = "";
string ficheroPDFIndexar = "";
string mMetadatos = "";
int numElementos = lsPDFIndexar.CheckedItems.Count;
this.Cursor = Cursors.WaitCursor;
bp.Minimum = 0;
bp.Maximum = numElementos - 1;
bp.Value = 0;
for (int i = 0; i <= lsPDFIndexar.CheckedItems.Count - 1; i++)
{
ficheroPDFIndexar = lsPDFIndexar.CheckedItems[i].ToString();
bp.Value = i;
lInfo.Text = Convert.ToString(i + 1) +
"/" + Convert.ToString(numElementos) +
" [" + Path.GetFileName(ficheroPDFIndexar) + "]";
Application.DoEvents();
//obtener metadatos del fichero PDF
mMetadatos = util.obtenerMetaDatosFicheroPDF(ficheroPDFIndexar);
//obtener el texto del PDF
textoIndexadoPDFActual = util.obtenerTextoFicheroPDF(ficheroPDFIndexar);
if (textoIndexadoPDFTodos != "")
{
textoIndexadoPDFTodos = textoIndexadoPDFTodos +
Environment.NewLine + Environment.NewLine +
"==================================" +
Environment.NewLine + Environment.NewLine +
"Fichero: " + ficheroPDFIndexar + Environment.NewLine +
mMetadatos + Environment.NewLine + textoIndexadoPDFActual;
}
else
{
textoIndexadoPDFTodos =
"Fichero: " + ficheroPDFIndexar + Environment.NewLine +
mMetadatos + Environment.NewLine + textoIndexadoPDFActual;
}
}
txtResultadoIndexacionPDF.Text = textoIndexadoPDFTodos;
this.Cursor = Cursors.Default;
lInfo.Text = "Proceso de indexación de PDF finalizado";
bp.Value = 0;
MessageBox.Show("Proceso de indexación de PDF finalizado correctamente.",
"Fin proceso", MessageBoxButtons.OK, MessageBoxIcon.Information);
}
else
{
btInsertarDocPDFIndexar.Focus();
MessageBox.Show("Debe chequear los ficheros PDF a indexar a pantalla.",
"Seleccionar PDF", MessageBoxButtons.OK, MessageBoxIcon.Information);
}
}
private void btSelTodos_Click(object sender, EventArgs e)
{
for (int i = 0; i < lsPDFIndexar.Items.Count; i++)
{
lsPDFIndexar.SetItemChecked(i, true);
}
}
private void btNinguno_Click(object sender, EventArgs e)
{
for (int i = 0; i < lsPDFIndexar.Items.Count; i++)
{
lsPDFIndexar.SetItemChecked(i, false);
}
}
private void btInvertir_Click(object sender, EventArgs e)
{
for (int i = 0; i < lsPDFIndexar.Items.Count; i++)
{
lsPDFIndexar.SetItemChecked(i, ! lsPDFIndexar.GetItemChecked(i));
}
}
private void bConectar_Click(object sender, EventArgs e)
{
if (txtTabla.Text != "")
{
try
{
if (lsODBC.Text != "")
{
util.conexionBDODBC = new OdbcConnection("dsn=" + lsODBC.Text +
";UID=" + txtUsuario.Text + ";PWD=" + txtContrasena.Text + ";");
}
else
{
if (txtPuerto.Text != "")
{
util.conexionBDODBC = new OdbcConnection("DRIVER={" + lsMotor.Text +
"};SERVER=" + txtServidor.Text + "; PORT=" + txtPuerto.Text +
";UID=" + txtUsuario.Text +
";PWD=" + txtContrasena.Text + ";" +
";DATABASE=" + txtBD.Text + ";");
}
else
{
util.conexionBDODBC = new OdbcConnection("DRIVER={" + lsMotor.Text +
"};SERVER=" + txtServidor.Text + ";UID=" + txtUsuario.Text +
";PWD=" + txtContrasena.Text + ";" +
";DATABASE=" + txtBD.Text + ";");
}
}
util.conexionBDODBC.Open();
if (util.conexionBDODBC.State == ConnectionState.Open)
{
bDesconectar.Enabled = true;
bConectar.Enabled = false;
OdbcCommand comandoSQL;
string consultaSQL;
consultaSQL = "Select count(*) from " + txtTabla.Text;
try
{
comandoSQL = new OdbcCommand(consultaSQL, util.conexionBDODBC);
int numeroRegistros = Convert.ToInt32(comandoSQL.ExecuteScalar());
MessageBox.Show("La tabla " + txtTabla.Text + " existe con " +
Convert.ToString(numeroRegistros) + " registros.", "Conexión BD",
MessageBoxButtons.OK, MessageBoxIcon.Information);
beConectadoBD.Text = "Conectado a BD";
bDesconectar.Enabled = true;
bConectar.Enabled = false;
}
catch (Exception ex)
{
util.conexionBDODBC.Close();
bDesconectar.Enabled = false;
bConectar.Enabled = true;
MessageBox.Show("Error al ejecutar SQL: " +
System.Environment.NewLine + System.Environment.NewLine +
ex.GetType().ToString() + System.Environment.NewLine +
ex.Message, "Error",
MessageBoxButtons.OK, MessageBoxIcon.Error);
}
}
else
{
beConectadoBD.Text = "No conectado a BD";
bDesconectar.Enabled = false;
bConectar.Enabled = true;
MessageBox.Show("No conectado a la base de datos.", "Conexión BD",
MessageBoxButtons.OK, MessageBoxIcon.Exclamation);
}
}
catch (Exception error)
{
bDesconectar.Enabled = false;
bConectar.Enabled = true;
beConectadoBD.Text = "No conectado a BD";
util.conexionBDODBC.Close();
MessageBox.Show("Error de base de datos: " +
System.Environment.NewLine + System.Environment.NewLine +
error.GetType().ToString() + System.Environment.NewLine +
error.Message, "Error al crear PDF",
MessageBoxButtons.OK, MessageBoxIcon.Error);
}
}
else
{
MessageBox.Show("Debe indicar el nombre de la tabla de " +
"la BD donde se crearán los registros " +
"con el indexado del los PDF.", "Tabla",
MessageBoxButtons.OK, MessageBoxIcon.Exclamation);
txtTabla.Focus();
}
}
private void btListaODBC_Click(object sender, EventArgs e)
{
SortedList listaODBC = new System.Collections.SortedList();
lsODBC.Items.Clear();
listaODBC = util.obtenerDataSourcesSistema();
foreach (DictionaryEntry key in listaODBC)
{
lsODBC.Items.Add(key.Key.ToString());
}
listaODBC = util.obtenerDataSourcesUsuario();
foreach (DictionaryEntry key in listaODBC)
{
lsODBC.Items.Add(key.Key.ToString());
}
}
private void btGuardarTextoFichero_Click(object sender, EventArgs e)
{
dlGuardar.Title = "Selección de carpeta y fichero de " +
"texto donde se guardará la indexación";
dlGuardar.Filter = "Texto (*.txt)|*.txt|Todos los ficheros (*.*)|*.*";
dlGuardar.DefaultExt = "txt";
dlGuardar.FilterIndex = 1;
dlGuardar.CheckFileExists = false;
dlGuardar.OverwritePrompt = true;
if (dlGuardar.ShowDialog() == DialogResult.OK)
{
try
{
StreamWriter ficheroTexto = new StreamWriter(dlGuardar.FileName,
false, System.Text.Encoding.Default);
ficheroTexto.Write(txtResultadoIndexacionPDF.Text);
ficheroTexto.Flush();
ficheroTexto.Close();
MessageBox.Show("Fichero de texto guardado correctamente.",
"Fichero guardado",
MessageBoxButtons.OK, MessageBoxIcon.Information);
}
catch (Exception ex)
{
MessageBox.Show("Error al guardar fichero de texto: " +
System.Environment.NewLine + System.Environment.NewLine +
ex.GetType().ToString() + System.Environment.NewLine +
ex.Message, "Error",
MessageBoxButtons.OK, MessageBoxIcon.Error);
}
}
}
private void bDesconectar_Click(object sender, EventArgs e)
{
try
{
util.conexionBDODBC.Close();
bDesconectar.Enabled = false;
bConectar.Enabled = true;
beConectadoBD.Text = "No conectado a BD";
bConectar.Focus();
}
catch (Exception error)
{
bDesconectar.Enabled = false;
bConectar.Enabled = true;
MessageBox.Show("Error de base de datos: " +
System.Environment.NewLine + System.Environment.NewLine +
error.GetType().ToString() + System.Environment.NewLine +
error.Message, "Error al crear PDF",
MessageBoxButtons.OK, MessageBoxIcon.Error);
}
}
private void btIndexarPDFBD_Click(object sender, EventArgs e)
{
if (util.conexionBDODBC.State == ConnectionState.Open)
{
if (lsPDFIndexar.CheckedItems.Count != 0)
{
string textoIndexadoPDF = "";
string ficheroPDFIndexar = "";
string mMetadatos = "";
int numElementos = lsPDFIndexar.CheckedItems.Count;
this.Cursor = Cursors.WaitCursor;
bp.Minimum = 0;
bp.Maximum = numElementos - 1;
bp.Value = 0;
for (int i = 0; i <= numElementos - 1; i++)
{
bp.Value = i;
ficheroPDFIndexar = lsPDFIndexar.CheckedItems[i].ToString();
lInfo.Text = Convert.ToString(i + 1) +
"/" + Convert.ToString(numElementos) +
" [" + Path.GetFileName (ficheroPDFIndexar) + "]";
Application.DoEvents();
//Obtener metadatos del fichero PDF
mMetadatos = util.obtenerMetaDatosFicheroPDF(ficheroPDFIndexar);
//obtener texto indexado del PDF
textoIndexadoPDF = util.obtenerTextoFicheroPDF(ficheroPDFIndexar);
util.insertarRegistroBD(ficheroPDFIndexar, textoIndexadoPDF,
mMetadatos, txtCampoFicheroPDF.Text,
txtCampoTextoPDF.Text, txtCampoMetadatosPDF.Text,
txtTabla.Text, txtCampoFecha.Text, opBDIndexarReemplazar.Checked);
}
this.Cursor = Cursors.Default;
lInfo.Text = "Proceso de indexación de PDF finalizado";
bp.Value = 0;
util.conexionBDODBC.Close();
bConectar.Enabled = true;
bDesconectar.Enabled = false;
beConectadoBD.Text = "No conectado a BD";
MessageBox.Show("Proceso de indexación de PDF finalizado correctamente.",
"Fin proceso", MessageBoxButtons.OK, MessageBoxIcon.Information);
}
else
{
btInsertarDocPDFIndexar.Focus();
MessageBox.Show("Debe chequear los ficheros PDF a indexar a base de datos.",
"Seleccionar PDF", MessageBoxButtons.OK, MessageBoxIcon.Information);
}
}
else
{
MessageBox.Show("Debe estar conectado a la base de datos para " +
"realizar la indexación de los ficheros PDF seleccionados.",
"Error al crear PDF", MessageBoxButtons.OK, MessageBoxIcon.Information);
}
}
private void formIndexarPDF_FormClosed(object sender, FormClosedEventArgs e)
{
Utilidades proUtilidades = new Utilidades();
cifrarAES cifradoAES = new cifrarAES();
proUtilidades.guardarValorConfiguracion("BD.ODBC", lsODBC.Text);
proUtilidades.guardarValorConfiguracion("BD.Motor", lsMotor.Text);
proUtilidades.guardarValorConfiguracion("BD.Servidor", txtServidor.Text);
proUtilidades.guardarValorConfiguracion("BD.Usuario", txtUsuario.Text);
proUtilidades.guardarValorConfiguracion("BD.Contraseña",
cifradoAES.cifrarTextoAES (txtContrasena.Text,
"AjpdSoft_Frase_Encriptado", "AjpdSoft_Frase_Encriptado",
"MD5", 22, "1234567891234567", 128));
proUtilidades.guardarValorConfiguracion("BD.Base_Datos", txtBD.Text);
proUtilidades.guardarValorConfiguracion("BD.Puerto", txtPuerto.Text);
proUtilidades.guardarValorConfiguracion("BD.Tabla", txtTabla.Text);
proUtilidades.guardarValorConfiguracion("BD.Campo_Texto_Indexado",
txtCampoTextoPDF.Text);
proUtilidades.guardarValorConfiguracion("BD.Campo_Fecha",
txtCampoFecha.Text);
proUtilidades.guardarValorConfiguracion("BD.Campo_Metadatos",
txtCampoMetadatosPDF.Text);
proUtilidades.guardarValorConfiguracion("BD.Campo_Fichero_PDF",
txtCampoFicheroPDF.Text);
}
private void btSQL_Click(object sender, EventArgs e)
{
formSQL frmSQL = new formSQL();
frmSQL.ShowDialog();
}
private void formIndexarPDF_Load(object sender, EventArgs e)
{
Utilidades proUtilidades = new Utilidades();
cifrarAES cifradoAES = new cifrarAES();
lsODBC.Text =
proUtilidades.leerValorConfiguracion("BD.ODBC");
lsMotor.Text =
proUtilidades.leerValorConfiguracion("BD.Motor");
txtServidor.Text =
proUtilidades.leerValorConfiguracion("BD.Servidor");
txtUsuario.Text =
proUtilidades.leerValorConfiguracion("BD.Usuario");
txtContrasena.Text =
cifradoAES.descifrarTextoAES(
proUtilidades.leerValorConfiguracion("BD.Contraseña"),
"AjpdSoft_Frase_Encriptado", "AjpdSoft_Frase_Encriptado",
"MD5", 22, "1234567891234567", 128);
txtBD.Text =
proUtilidades.leerValorConfiguracion("BD.Base_Datos");
txtPuerto.Text =
proUtilidades.leerValorConfiguracion("BD.Puerto");
txtTabla.Text=
proUtilidades.leerValorConfiguracion("BD.Tabla");
txtCampoTextoPDF.Text =
proUtilidades.leerValorConfiguracion("BD.Campo_Texto_Indexado");
txtCampoFecha.Text =
proUtilidades.leerValorConfiguracion("BD.Campo_Fecha");
txtCampoMetadatosPDF.Text =
proUtilidades.leerValorConfiguracion("BD.Campo_Metadatos");
txtCampoFicheroPDF.Text =
proUtilidades.leerValorConfiguracion("BD.Campo_Fichero_PDF");
}
private void toolStripStatusLabel1_Click_1(object sender, EventArgs e)
{
//abrir navegador por defecto y acceder a la URL www.ajpdsoft.com
System.Diagnostics.Process.Start("http://www.ajpdsoft.com");
}
}
}
Crear base de datos y tabla en PostgreSQL para guardar indexación de PDF
En el ejemplo usaremos un servidor de base de datos con PostgreSQL. La aplicación AjpdSoft Indexar Texto PDF C# iTextSharpadmite cualquier motor de base de datos con soporte de ODBC: Oracle, MySQL, SQLite, Microsoft Access, Microsoft SQL Server, Firebird, PostgreSQL, etc.
A continuación mostramos algunos tutoriales para instalar PostgreSQL tanto en sistemas operativos Windows como Linux:
Una vez que tengamos disponible el servidor o equipo con el motor de base de datos y hayamos instalado el administrador pgAdmin III, abriremos este último, nos conectaremos al servidor. Pulsaremos con el botón derecho del ratón sobre "Databases", seleccionaremos "New Database":
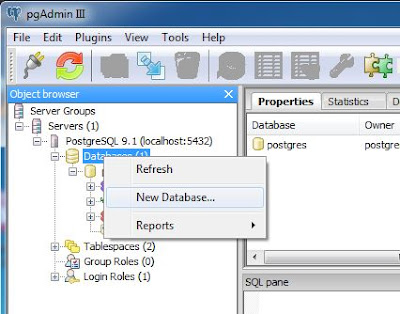
En la pestaña "Properties", en el campo "Name", introduciremos el nombre para la base de datos que usaremos para guardar el texto extraído de los ficheros PDF, por ejemplo "indexadopdf". Pulsaremos "OK":
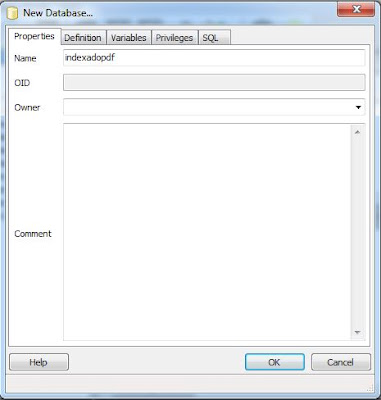
Nuestra base de datos PostgreSQL aparecerá en el árbol, desplegaremos "indexadopdf" y accederemos a "Schemas", en "Public" pulsaremos con el botón derecho del ratón y seleccionaremos "New Object", en el submenú emergente pulsaremos en "New Table":

Introduciremos en la pestaña "Properties", en el campo "Name" el nombre para la tabla, por ejemplo "indexpdf":

Ahora añadiremos las columnas para la tabla "indexpdf", para ello pulsaremos en la pestaña "Columns" y pulsaremos "Add":

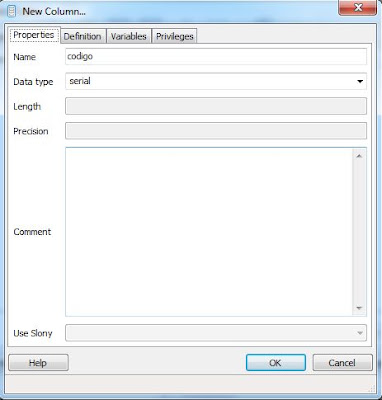
En la pestaña "Properties" de la ventana "New Column", introduciremos el nombre para la columna, por ejemplo crearemos una columna con autoincremento que será la clave primaria de la tabla (primary key). En "Name" introduciremos "codigo" y en "Data type" seleccionaremos "serial". Pulsaremos "OK":
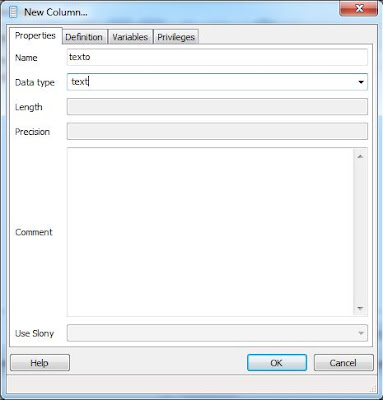
De la misma forma, añadiremos la columna o campo "texto", con tipo de datos (Data type) "text". Este campo será el que guarde el contenido de texto de cada fichero PDF indexado. Por lo tanto debe ser un tipo de dato que admita cualquier texto de cualquier tamaño:
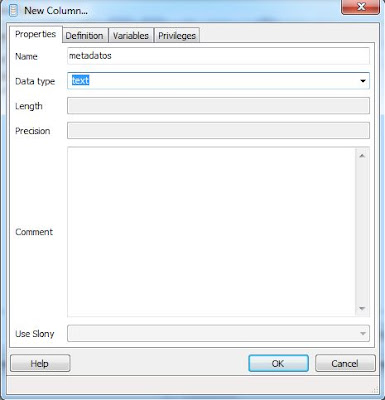
Crearemos también el campo "metadatos" que será donde guardemos los metadatos extraídos del fichero PDF. Este campo no necesita ser de tipo "text" pues los metadatos no suelen tener más de 500 caracteres. Pero los metadatos pueden ser variables por lo que lo crearemos de tipo "text":
Crearemos también la columna "ficheropdf" que contendrá la ruta y nombre del fichero PDF indexado, esta columna puede ser de tipo de datos "character varying" y de tamaño 500 (Length):
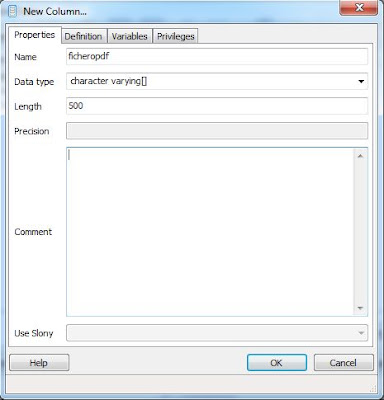
Añadiremos la columna "fechaindexacion" donde la aplicación guardará la fecha en la que realizó la extracción del texto del fichero PDF. Llamaremos a este campo "fechaindexacion" y de tipo "date":
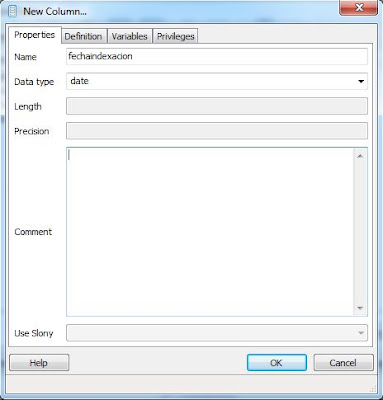
Por último crearemo la clave primaria (primary key). Para ello desde la ventana de "New Table", pulsaremos en la pestaña "Constraints", seleccionaremos "Primary Key" y pulsaremos "Add":
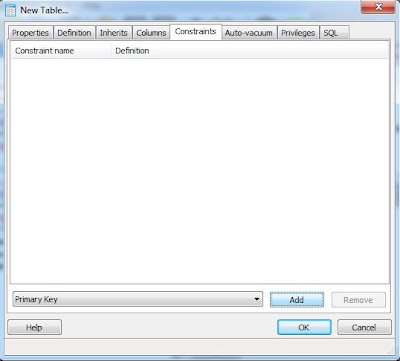
Introduciremos el nombre para la clave primaria, por ejemplo "pk_codigo_indexacionpdf":
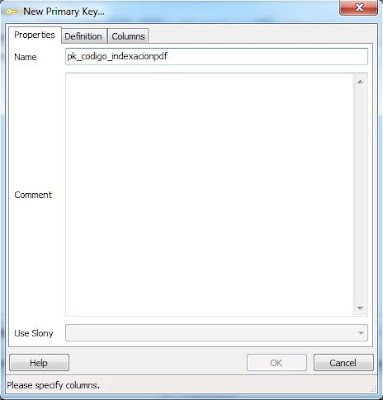
En la pestaña "Columns", en "Column" seleccionaremos "codigo" y pulsaremos "Add":

Tras añadir la clave primaria pulsaremos "OK" en la ventana "New Primary Key":
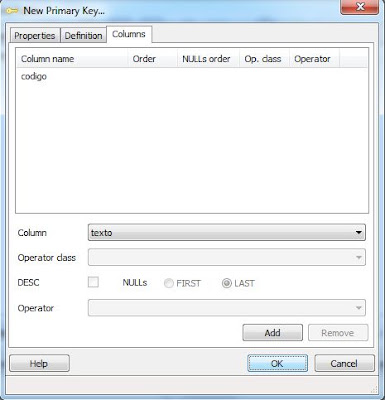
Tras crear las columnas y las constraints (restricciones) como la clave primaria, pulsaremos "OK" para crear definitivamente la tabla "indexpdf":

De esta forma ya tendremos la tabla "indexpdf" creada en la base de datos "indexadopdf" de nuestro servidor con PostgreSQL:

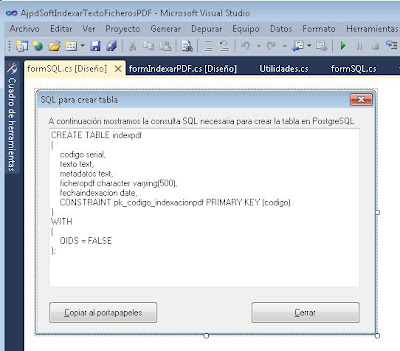
La consulta SQL para crear la tabla anterior:
CREATE TABLE indexpdf
(
codigo serial,
texto text,
metadatos text,
ficheropdf character varying(500),
fechaindexacion date,
CONSTRAINT pk_codigo_indexacionpdf PRIMARY KEY (codigo)
)
WITH (
OIDS = FALSE
)
;
Crear origen de datos ODBC para acceso a PostgreSQL en PC con Windows 7
A continuación explicaremos cómo crear un origen de datos ODBC para acceso al servidor con PostgreSQL (puede ser Windows o Linux). Para crear un origen de datos ODBC de 64 bits (si hemos instalado el servidor con PostgreSQL x64) seguiremos los pasos que indica este tutorial:
Para aclarar el manido tema de los 64 ó 32 bits vamos a mostrar a continuación las posibles combinaciones, es importante conocerlas para saber qué ODBC instalar y cuál no. Por un lado el servidor de PostgreSQL, que puede tener un sistema operativo de 32 ó de 64 bits, si el sistema operativo es de 32 bits es evidente que PostgreSQL sólo podrá ser de 32 bits. Si el servidor tiene un sistema operativo de 64 bits podremos instalar PostgreSQL de 32 bits o PostgreSQL de 64 bits. Si instalamos PostgreSQL de 32 bits en el servidor los clientes (ODBC y demás tipos de conexión) deberán ser de 32 bits. Ahora bien, si nuestro servidor con PostgreSQL es de 64 bits e instalamos PostgreSQL de 64 bits tendremos las siguientes posibilidades en los equipos cliente que se conectarán a este servidor:
1. Aplicación cliente de 32 bits por lo que ésta sólo admitirá driver ODBC de 32 bits. Aunque tengamos el sistema operativo de 64 bits, en este caso deberemos instalar el v de 32 bits correspondiente para PostgreSQL. Aunque el servidor PostgreSQL sea de 64 bits, admitirá conexiones de un ODBC de 32 bits. En esta circunstancia hay que tener en cuenta que si el equipo cliente tiene como sistema operativo Microsoft Windows 7 x64 (válido para Windows Vista, Windows Server 2008 y Windows 8), para crear un origen de datos de 32 bits hay que ejecutar el fichero:
C:/Windows/SysWOW64/odbcad32.exe
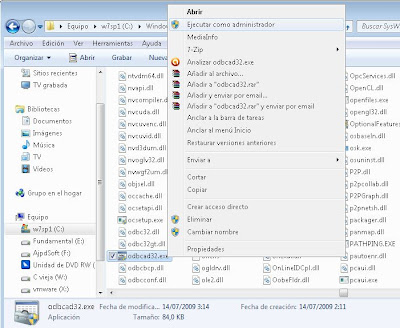
El fichero anterior mostrará los orígenes de datos ODBC del equipo para 32 bits x86. Desde aquí podrá crearse un origen de datos ODBC de 32 bits que será el que pueda usar una aplicación cliente de 32 bits. Desde la pestaña "DSN de sistema" (para que el ODBC esté disponible para todos los usuarios) pulsaremos en "Agregar":
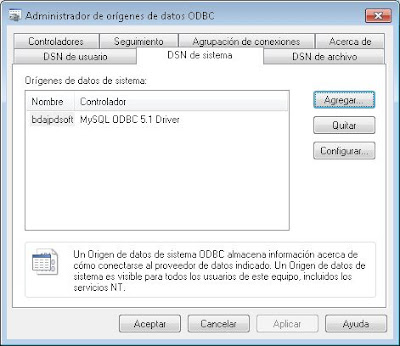
Seleccionaremos el origen de datos a usar, en nuestro caso "PostgreSQL ANSI". Por supuesto, antes de crear el origen de datos debe estar instalado el driver correspondiente (como ya hemos explicado aquí):

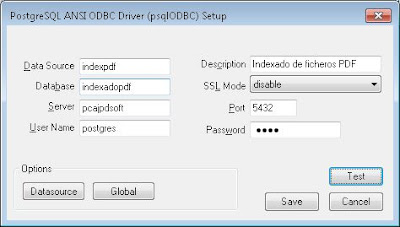
Introduciremos los datos para el nuevo origen de datos ODBC:
- Data Source: nombre del origen de datos, por ejemplo "indexpdf".
- Description: breve descripción del origen de datos, por ejemplo "Indexado de texto de ficheros PDF".
- Database: nombre que le hayamos dado a la base de datos de PostgreSQL, en nuestro ejemplo "indexadopdf".
- Server: IP o hosname del servidor con PostgreSQL.
- Port: puerto para conexión con PostgreSQL, por defecto 5432.
- User Name: nombre de usuario de PostgreSQL con permisos suficientes para acceso de consulta y modificación de la tabla en cuestión.
- Password: contraseña para el usuario anterior.
Pulsando en el botón "Test" podremos realizar una prueba de conexión:
Si todo es correcto nos mostrará un mensaje con el texto "Connection successful":
2. Aplicación cliente de 64 bits, esta aplicación soportará drivers ODBC de 32 bits y de 64 bits, por lo tanto podremos crear el origen de datos en el equipo de la forma habitual, desde "Herramientas administrativas" - "Orígenes de datos ODBC", como indicamos aquí:
En el siguiente post de nuestros foros explicamos cómo crear una aplicación de 64 bits con Visual C# y explicamos también cómo crear un origen de datos ODBC de 64 o 32 bits:
Artículos relacionados
Créditos
Artículo realizado íntegramente por Alonsojpd miembro fundador del Proyecto AjpdSoft.
Artículo en inglés.
Anuncios
