|
Hardware: Optimización protocolo de coherencia de caché MESI en aplicaciones multitarea

Mostramos en este tutorial qué es el protocolo MESI y cómo funciona en pequeños sistemas con multiprocesadores simétricos. Indicamos la optimización que supone el protocolo MESI en el caso de transferencia de caché a caché y algunos resultados de simulaciones en determinadas condiciones.
Introducción al protocolo MESI
La coherencia de caché hace referencia a la integridad de los datos almacenados en las cachés locales de los recursos compartidos. La coherencia de la caché es un caso especial de la coherencia de memoria. Múltiples caches con recursos comunes: cuando los clientes de un sistema, en particular las CPU en un multiprocesador, mantienen cachés de una memoria compartida, los conflictos crecen. Varios modelos y protocolos han sido desarrollados para mantener la coherencia de la caché, tales como protocolo MSI, protocolo MESI, protocolo MOSI y el protocolo MOESI. La elección de un modelo de consistencia es crucial a la hora de diseñar un sistema de caché coherente. Los modelos de coherencia difieren en rendimiento y escalabilidad, por lo que deben ser evaluados para cada sistema diseñado. Además, las transiciones entre estados en una implementación en concreto de estos protocolos pueden variar. Por ejemplo una implementación puede elegir diferentes transiciones para actualizar y actualiza tales como actualización-en-lectura, actualización-en-escritura, invalidación-en-lectura, o invalidación-en-escritura. La elección de una transición puede afectar a la cantidad de tráfico entre cachés, lo que a su vez podría afectar al ancho de banda disponible por las cachés para la operación actual. Esto debe ser tenido en consideración en el diseño de software distribuido que podría causar problemas de contención entre cachés de múltiples procesadores. El nombre del protocolo (MESI) viene de los nombres de los estados que puede tomar una línea: modificada, exclusiva, compartida e inválida que en inglés significan Modified, Exclusive, Shared, Invalid, y lo cierto es que este nombre se usa más que el de Illinois.
E - Exclusive (Exclusivo): la línea de caché sólo se encuentra en la caché actual, pero está "limpia"; coincide con el valor de la memoria principal. S - Shared (Compartido): indica que esta línea de caché puede estar duplicada en otras cachés. I - Invalid (Inválido): indica que esta línea de caché no es válida. Una línea que es propiedad de cualquier caché puede estar como exclusiva o modificada. Las líneas que están en el estado compartida no son propiedad de nadie en concreto. La aproximación MESI permite la determinación de si una línea es compartida o no cuando se carga. Una línea modificada es enviada directamente al peticionario desde la caché que la contiene. Esto evita la necesidad de enviar comandos de invalidación para todas aquellas líneas que no estaban compartidas. Se puede leer de caché en cualquier estado excepto en Inválidos. Una línea inválida puede ser cogida (de los estados Compartido o Exclusivo) para satisfacer una lectura. Una escritura sólo puede ser llevada a cabo si la línea de caché está en estado Modificado o Exclusivo. Si está en estado Compartido todas las otras copias en otras cachés deben ser puestas en estado Inválido antes. Esto se hace habitualmente con una operación broadcast. Una caché puede cambiar el estado de una línea en cualquier momento, pasándolo a estado Inválido. Una línea Modificada debe ser escrita antes. Una caché que contenga una línea en estado Modificado debe sondear (interceptar) todos los intentos de lectura (de todas las CPU del sistema) a la memoria principal y copiar los datos que tiene. Esto se hace habitualmente forzando la lectura back off (cancelar el bus de transferencia a memoria), para luego escribir los datos en memoria principal y cambiar la línea de caché a estado Compartido. Una caché que contenga una línea en estado Compartido debe también sondear todas las operaciones broadcast inválidas de otras CPU, y descartar la línea (cambiándola a estado Inválido) una vez hecho. Una caché que contenga una línea en estado Exclusivo también debe sondear todas las peticiones de lecturas del resto de CPU y cambiar la línea a estado Compartido una vez hecho. Los estados Modificado y Exclusivo son siempre precisos: corresponden a los poseedores de la línea correcta en el sistema. El estado Compartido puede ser impreciso: si alguna otra CPU descarga una línea Compartida, y esta CPU es la única que tiene una copia, la línea no será cambiada a estado Exclusivo. En ese sentido el estado Exclusivo es una optimización oportunista: si la CPU quiere modificar la línea de caché a estado Compartido, es necesario un intercambio por el bus para invalidar cualquier otra copia en caché. El estado Compartido permite modificar una línea de caché sin ningún intercambio por el bus. Optimización del protocolo MESILa correcta optimización de los protocolos generales de uso de la caché, en el caso de multiprocesamiento simétrico con memoria compartida, puede suponer un importante incremento en el rendimiento general de la capacidad de procesamiento de un sistema informático. La optimización que se busca, en la transferencia caché a caché, es significativa porque las condiciones para que se produzca suceden con mucha frecuencia cuando los hilos de las aplicaciones multitarea se ejecutan en procesadores separados de una máquina SMP (Symmetric Multi-Processing o Multiproceso Simétrico). En el apartado siguiente se muestran con qué frecuencia: A continuación se muestra una explicación sobre cómo funciona un procesador que no implementa esta optimización, un PowerPC 604 y un procesador que sí la implementa, un Pentium II. "Espionaje" en acierto de lectura sin transferencias caché a caché
En el caso de la figura anterior, un ejemplo de funcionamiento de la a caché de un PowerPC, la caché B tiene actualmente una línea de datos. En ella se han modificado los datos, pero no se han escrito de nuevo en la memoria principal, por lo que está en el estado Modificado. La caché A detecta la dirección y comprueba su valor, resultando un acierto. La caché B "espía" la dirección y comprueba su caché encontrando un acierto. Si se permite que la transacción continúe, la caché A recibiría una copia no válida de los datos. Esto hace que la transacción se aborte inmediatamente y hace esperar a todos los agentes del bus de datos un ciclo de reloj, antes de hacer una nueva solicitud. Durante este ciclo de reloj, la caché que contiene los datos modificados debe tener acceso al bus de datos (ganando el arbitraje) y reescribe los datos en la memoria. Después de esta transacción los datos en la caché B se marcan como Exclusivo, ya que no se han modificado, sin embargo, no existen en ninguna otra caché. Cuando finaliza la transacción, la caché A pide otra vez al bus de datos que solicite una vez más la línea de memoria. Cuando esto sucede la caché B solicita de nuevo esta lectura, pero esta vez solo afirma la señal. La transacción se completa con normalidad, con la memoria del sistema suministrando los datos (incurriendo en la latencia del acceso a la DRAM y en el ciclo de reloj), pero tanto la caché A como la B marcan la línea como si estuviera en estado Compartido.
"Espionaje" en acierto de lectura con transferencias caché a caché
En el caso del Pentium II, la caché B tiene una línea modificada. Cuando la caché A hace una petición desde la memoria, la caché B comprueba esta dirección y ve que tiene una copia modificada. La caché B genera la señal de Modificado y los agentes implicados cambian los roles. La caché A se prepara para recibir los datos desde la otra caché y marcarla como Compartida en vez de Exclusiva, entonces la caché B se hace cargo de proporcionar los datos de la memoria. Esto cambiará el estado de la línea a Compartida. Por último, la memoria cambiará, de proporcionar los datos, a almacenarlos desde la caché B hasta que sea necesario escribirlos de nuevo en la DRAM. El ahorro en ciclos de reloj que supone el método "transferencia caché a caché" frente al método de "no transferencia de caché a caché" se podrá entender con el siguiente ejemplo. Supongamos que cada sistema se ejecuta en un bus de datos de 128 bits a 100 MHz. Supongamos también que los bloques de cada caché son de 32 bytes de longitud. Por último, digamos que una caché L2 tarda 1 ciclo de reloj en operar, y que estamos utilizando DRAM normal con un tiempo de acceso de 60 ns. Finalmente supongamos que necesitamos 1 ciclo de reloj para solicitar el bus de datos y otro más para poner la dirección en el bus de direcciones. Dada esta configuración, solicitar 32 bytes de memoria DRAM consumirán 1 ciclo de reloj, conseguir la dirección otro ciclo de reloj, 6 ciclos para acceder a la DRAM y 2 ciclos para transferir los datos, es decir, un total de 10 ciclos de reloj. Solicitar los mismos 32 bytes desde otra caché, en cambio, solo tomará 1 ciclo de reloj, otro ciclo para obtener la dirección, 1 ciclo para el acceso y 2 ciclos para transferir los datos, con un total de 5 ciclos de reloj, es decir, la mitad de tiempo. Para el caso de una línea modificada el ahorro es aún mayor: 1 ciclo para la solicitud, 1 para obtener la dirección, 1 para cancelar la transacción, 10 ciclos para volver a escribir los datos, y luego otros 10 para recuperarla de nuevo desde la memoria, es decir, un total de 23 ciclos de reloj. Más adelante se podrá comprobar este ejemplo en los resultados de la simulación.
Rendimiento del multiproceso MESIA la hora de determinar el rendimiento de un multiprocesador con arquitectura MESI hay que tener en cuenta varios fenómenos combinables, ya que el rendimiento total de la caché es una combinación del comportamiento del tráfico causado por fallos de caché en un uniprocesador y el tráfico causado por la comunicación entre cachés, lo que puede dar lugar a invalidaciones. El rendimiento se ve afectado por el número de procesadores, tamaño de la caché y tamaño del bloque, llevando al sistema a un comportamiento surgido de la combinación de estos efectos. Algunas características del protocolo de invalidación MESI que influyen en el rendimiento son:
Como ya hemos comentado anteriormente, el ancho de banda del bus y la memoria van a influir en el rendimiento del protocolo MESI, puesto que es lo que más se demanda en un multiprocesador basado en bus, y esto hace que cualquier protocolo de invalidación, como es el caso de MESI, sea idóneo para sistemas que requieren mucha migración de procesos o sincronización. Para un rendimiento adecuado del protocolo MESI hay que controlar los fallos en la caché que puedan producirse por la invalidación iniciada por otro procesador previamente al acceso a la caché puesto que incrementaría el tráfico en el bus.
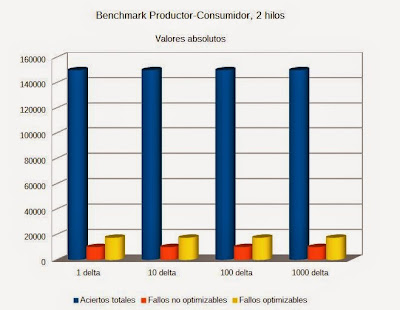
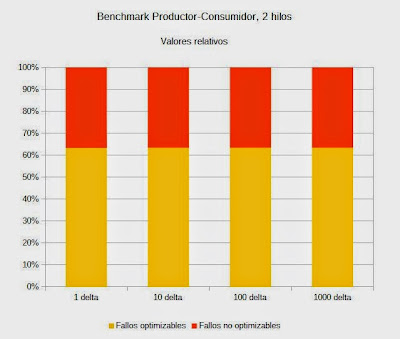
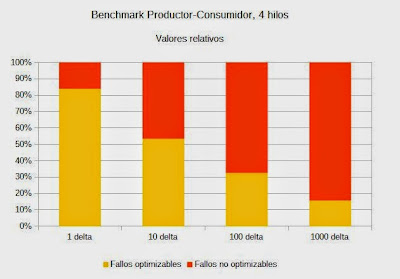
Resultados de la simulación y conclusiónResultados de Productor-ConsumidorEste benchmark muestra el rendimiento del procesador en el clásico modelo cliente-servidor, aplicado a la computación multihilo. Se han registrado los valores utilizando 2 y 4 hilos en diferentes desfases temporales delta.
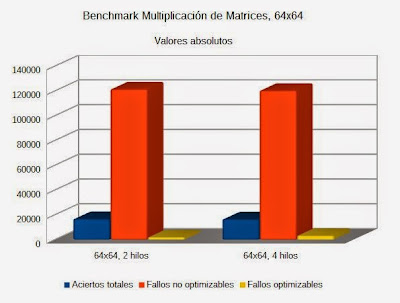
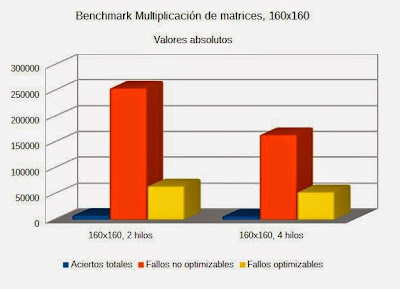
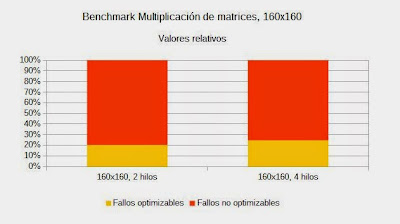
Resultados de la multiplicación de matricesEste benchmark muestra el rendimiento del procesador en la multiplicación de dos matrices cuadradas de 3 dimensiones diferentes (4x4, 64x64 y 160x160), con los valores utilizando 2 y 4 hilos. Aunque tiene un grado menor de compartición de datos que el benchmark Productor-Consumidor, es sin embargo lo suficientemente significativo, ya que la multiplicación de matrices opera en diferentes partes que poseen un considerable grado de coordinación y solapamiento de las líneas de datos de las cachés.
Bibliografía
CréditosArtículo realizado por:
Para la Universidad Internacional Isabel I de Castilla. Anuncios
Enviado el Martes, 17 marzo a las 01:05:16 por ajpdsoft
|
|